
灵活图RAG
STDIO混合搜索平台结合向量相似性全文搜索和知识图谱
混合搜索平台结合向量相似性全文搜索和知识图谱
Flexible GraphRAG is a platform supporting document processing, knowledge graph auto-building, RAG and GraphRAG setup, hybrid search (fulltext, vector, graph) and AI Q&A query capabilities.
A configurable hybrid search system that optionally combines vector similarity search, full-text search, and knowledge graph GraphRAG on document processed from multiple data sources (filesystem, Alfresco, CMIS, etc.). Built with LlamaIndex which provides abstractions for allowing multiple vector, search graph databases, LLMs to be supported. It has both a FastAPI backend with REST endpoints and a Model Context Protocol (MCP) server for MCP clients like Claude Desktop, etc. Also has simple Angular, React, and Vue UI clients (which use the REST APIs of the FastAPI backend) for using interacting with the system.
| Sources Tab | Processing Tab | Search Tab | Chat Tab |
|---|---|---|---|
 |  |  |  |
| Sources Tab | Processing Tab | Search Tab | Chat Tab |
|---|---|---|---|
 |  |  |  |
| Sources Tab | Processing Tab | Search Tab | Chat Tab |
|---|---|---|---|
 |  |  |  |
| Sources Tab | Processing Tab | Search Tab | Chat Tab |
|---|---|---|---|
 |  |  |  |
/flexible-graphrag)/flexible-graphrag-mcp)/flexible-graphrag-ui)/docker)The system processes 15+ document formats through intelligent routing between Docling (advanced processing) and direct text handling:
.pdf - Advanced layout analysis, table extraction, formula recognition.docx, .xlsx, .pptx - Full structure preservation and content extraction.html, .htm, .xhtml - Markup structure analysis.csv, .xml, .json - Structured data processing.asciidoc, .adoc - Technical documentation with markup preservation.png, .jpg, .jpeg - OCR text extraction.tiff, .tif, .bmp, .webp - Layout-aware OCR processing.txt - Direct ingestion for optimal chunking.md, .markdown - Preserved formatting for technical documentsCRITICAL: When switching between different embedding models (e.g., OpenAI ↔ Ollama), you MUST delete existing vector indexes due to dimension incompatibility:
See VECTOR-DIMENSIONS.md for detailed cleanup instructions for each database.
Current configuration supports (via LlamaIndex vector store integrations)
Current configuration supports (via LlamaIndex abstractions, can be extended to cover others that LlamaIndex supports):
General Performance with LlamaIndex: OpenAI vs Ollama
Based on testing with OpenAI GPT-4o-mini and Ollama models (llama3.1:8b, llama3.2:latest, gpt-oss:20b), OpenAI consistently outperforms Ollama models in LlamaIndex operations.
When using Ollama (not OpenAI), configure these system environment variables before starting the Ollama service to optimize performance with limited resources and enable parallel processing:
# Context length for model processing OLLAMA_CONTEXT_LENGTH=8192 1. You can go down to 4096 with limited resources, or can go higher for improved speed and extraction quality say to 16384. 2. The full 128k possible context window for llama3.2:3b of 16.4GB of RAM for the key-value (KV) cache alone, in addition to the ~3GB needed for the model weights. The 128K token context window means the model can process and maintain awareness of approximately 96,240 words of text in a single interaction. By default, most inference engines (like llama.cpp, transformers, Ollama, etc.) will attempt to store both model weights and the KV cache in GPU VRAM if sufficient capacity exists, as this is fastest for inference. If the GPU does not have enough VRAM, or if specifically configured, the KV cache can be kept in system RAM (regular RAM), potentially with a significant speed penalty. # Debug logging (1 for debug, 0 to disable) # Log location on Windows: C:\Users\<username>\AppData\Local\Ollama\server.log # Useful for checking GPU memory availability and CPU fallback behavior OLLAMA_DEBUG=1 # Keep models loaded in memory for faster subsequent requests OLLAMA_KEEP_ALIVE=30m # Maximum number of models to keep loaded simultaneously (0 for no limit) OLLAMA_MAX_LOADED_MODELS=4 # Model storage directory (usually set automatically) # Windows example: C:\Users\<username>\.ollama\models OLLAMA_MODELS=C:\Users\<username>\.ollama\models # CRITICAL: Number of parallel requests Ollama can handle # Required for Flexible GraphRAG parallel file processing to avoid errors OLLAMA_NUM_PARALLEL=4
Important Notes:
.env fileOLLAMA_NUM_PARALLEL=4 is critical - prevents processing errors during parallel document ingestionOLLAMA_DEBUG=1 helps identify GPU memory issues that force CPU processing6-Document Ingestion Performance (OpenAI gpt-4o-mini)
| Graph Database | Ingestion Time | Search Time | Q&A Time |
|---|---|---|---|
| Neo4j | 11.31s | 0.912s | 2.796s |
| Kuzu | 15.72s | 1.240s | 2.187s |
| FalkorDB | 21.74s | 1.199s | 2.133s |
For complete performance results including 2-doc and 4-doc tests, Ollama comparisons, and detailed breakdowns, see docs/PERFORMANCE.md.
The system can be configured for RAG (Retrieval-Augmented Generation) without also GraphRAG This simpler deployment also only do setting up vectors for RAG. It will skip setup for GraphRAG: no auto-building Graphs / Knowledge Graphs in a Graph Database. The processing time will be faster. You can still do Hybrid Search (full text search + vectors for RAG). You can also still do AI Q&A Queries or Chats.
To enable RAG-only mode, configure these environment variables in your .env file:
Configure Search Database (choose one):
# Option 1: Elasticsearch SEARCH_DB=elasticsearch SEARCH_DB_CONFIG={"index_name": "documents", "host": "localhost", "port": 9200} # Option 2: OpenSearch SEARCH_DB=opensearch SEARCH_DB_CONFIG={"index_name": "documents", "host": "localhost", "port": 9201} # Option 3: Built-in BM25 SEARCH_DB=bm25 SEARCH_DB_CONFIG={"persist_dir": "./bm25_index"}
Configure Vector Database (choose one):
# Option 1: Neo4j (configure separately for vector use) VECTOR_DB=neo4j VECTOR_DB_CONFIG={"uri": "bolt://localhost:7687", "username": "neo4j", "password": "password"} # Option 2: Qdrant VECTOR_DB=qdrant VECTOR_DB_CONFIG={"host": "localhost", "port": 6333, "collection_name": "documents"} # Option 3: Elasticsearch (configure separately for vector use) VECTOR_DB=elasticsearch VECTOR_DB_CONFIG={"index_name": "vectors", "host": "localhost", "port": 9200} # Option 4: OpenSearch (configure separately for vector use) VECTOR_DB=opensearch VECTOR_DB_CONFIG={"index_name": "vectors", "host": "localhost", "port": 9201} # Option 5: Chroma (local mode - default) VECTOR_DB=chroma VECTOR_DB_CONFIG={"persist_directory": "./chroma_db", "collection_name": "documents"} # Option 5b: Chroma (HTTP mode - server required) VECTOR_DB=chroma VECTOR_DB_CONFIG={"host": "localhost", "port": 8001, "collection_name": "documents"} # Option 6: Milvus (scalable) VECTOR_DB=milvus VECTOR_DB_CONFIG={"host": "localhost", "port": 19530, "collection_name": "documents"} # Option 7: Weaviate (semantic search) VECTOR_DB=weaviate VECTOR_DB_CONFIG={"url": "http://localhost:8081", "class_name": "Documents"} # Option 8: Pinecone (managed serverless service) VECTOR_DB=pinecone VECTOR_DB_CONFIG={"api_key": "your_api_key", "region": "us-east-1", "cloud": "aws", "index_name": "documents", "metric": "cosine"} # Option 9: PostgreSQL (with pgvector) VECTOR_DB=postgres VECTOR_DB_CONFIG={"host": "localhost", "port": 5433, "database": "postgres", "username": "postgres", "password": "password"} # Option 10: LanceDB (modern embedded) VECTOR_DB=lancedb VECTOR_DB_CONFIG={"uri": "./lancedb", "table_name": "documents"}
Disable Knowledge Graph:
GRAPH_DB=none ENABLE_KNOWLEDGE_GRAPH=false
The MCP server provides 9 specialized tools for document intelligence workflows:
| Tool | Purpose | Usage |
|---|---|---|
get_system_status() | System health and configuration | Verify setup and database connections |
ingest_documents(data_source, paths) | Bulk document processing | Process files/folders from filesystem, CMIS, Alfresco |
ingest_text(content, source_name) | Custom text analysis | Analyze specific text content |
search_documents(query, top_k) | Hybrid document retrieval | Find relevant document excerpts |
query_documents(query, top_k) | AI-powered Q&A | Generate answers from document corpus |
test_with_sample() | System verification | Quick test with sample content |
check_processing_status(id) | Async operation monitoring | Track long-running ingestion tasks |
get_python_info() | Environment diagnostics | Debug Python environment issues |
health_check() | Backend connectivity | Verify API server connection |
Docker deployment offers two main approaches:
Best for: Development, external content management systems, flexible deployment
# Deploy only databases you need docker-compose -f docker/docker-compose.yaml -p flexible-graphrag up -d # Comment out services you don't need in docker-compose.yaml: # - includes/neo4j.yaml # Comment out if using your own Neo4j # - includes/kuzu.yaml # Comment out if not using Kuzu # - includes/qdrant.yaml # Comment out if using Neo4j, Elasticsearch, or OpenSearch for vectors # - includes/elasticsearch.yaml # Comment out if not using Elasticsearch # - includes/elasticsearch-dev.yaml # Comment out if not using Elasticsearch # - includes/kibana.yaml # Comment out if not using Elasticsearch # - includes/opensearch.yaml # Comment out if not using # - includes/alfresco.yaml # Comment out if you want to use your own Alfresco install # - includes/app-stack.yaml # Remove comment if you want backend and UI in Docker # - includes/proxy.yaml # Remove comment if you want backend and UI in Docker # (Note: app-stack.yaml has env config in it to customize for vector, graph, search, LLM using) # Run backend and UI clients outside Docker cd flexible-graphrag uv run start.py
Use cases:
Best for: Production deployment, isolated environments, containerized content sources
# Deploy everything including backend and UIs docker-compose -f docker/docker-compose.yaml -p flexible-graphrag up -d
Features:
Service URLs after startup:
Data Source Workflow:
To stop and remove all Docker services:
# Stop all services docker-compose -f docker/docker-compose.yaml -p flexible-graphrag down
Common workflow for configuration changes:
# Stop services, make changes, then restart docker-compose -f docker/docker-compose.yaml -p flexible-graphrag down # Edit docker-compose.yaml or .env files as needed docker-compose -f docker/docker-compose.yaml -p flexible-graphrag up -d
Modular deployment: Comment out services you don't need in docker/docker-compose.yaml
Environment configuration (for app-stack deployment):
docker/includes/app-stack.yamlhost.docker.internal for container-to-container communicationSee docker/README.md for detailed Docker configuration.
Create environment file (cross-platform):
# Linux/macOS cp flexible-graphrag/env-sample.txt flexible-graphrag/.env # Windows Command Prompt copy flexible-graphrag\env-sample.txt flexible-graphrag\.env # Windows PowerShell Copy-Item flexible-graphrag\env-sample.txt flexible-graphrag\.env
Edit .env with your database credentials and API keys.
Navigate to the backend directory:
cd project-directory/flexible-graphrag
Create a virtual environment using UV and activate it:
# From project root directory uv venv .\.venv\Scripts\Activate # On Windows (works in both Command Prompt and PowerShell) # or source .venv/bin/activate # on macOS/Linux
Install Python dependencies:
# Navigate to flexible-graphrag directory and install requirements cd flexible-graphrag uv pip install -r requirements.txt
Create a .env file by copying the sample and customizing:
# Copy sample environment file (use appropriate command for your platform) cp env-sample.txt .env # Linux/macOS copy env-sample.txt .env # Windows
Edit .env with your specific configuration. See docs/ENVIRONMENT-CONFIGURATION.md for detailed setup guide.
Production Mode (backend does not serve frontend):
Development Mode (frontend and backend run separately):
Choose one of the following frontend options to work with:
Navigate to the React frontend directory:
cd flexible-graphrag-ui/frontend-react
Install Node.js dependencies:
npm install
Start the development server (uses Vite):
npm run dev
The React frontend will be available at http://localhost:5174.
Navigate to the Angular frontend directory:
cd flexible-graphrag-ui/frontend-angular
Install Node.js dependencies:
npm install
Start the development server (uses Angular CLI):
npm start
The Angular frontend will be available at http://localhost:4200.
Note: If ng build gives budget errors, use npm start for development instead.
Navigate to the Vue frontend directory:
cd flexible-graphrag-ui/frontend-vue
Install Node.js dependencies:
npm install
Start the development server (uses Vite):
npm run dev
The Vue frontend will be available at http://localhost:3000.
From the project root directory:
cd flexible-graphrag uv run start.py
The backend will be available at http://localhost:8000.
Follow the instructions in the Frontend Setup section for your chosen frontend framework.
# Angular (may have budget warnings - safe to ignore for development) cd flexible-graphrag-ui/frontend-angular ng build # React cd flexible-graphrag-ui/frontend-react npm run build # Vue cd flexible-graphrag-ui/frontend-vue npm run build
Angular Build Notes:
angular.jsonnpm start to avoid build issuescd flexible-graphrag uv run start.py
The backend provides:
/api/*Backend API Endpoints:
/api/ingest, /api/search, /api/query, /api/status, etc.Frontend Deployment:
http://localhost:8000/api/The project includes a sample-launch.json file with VS Code debugging configurations for all three frontend options and the backend. Copy this file to .vscode/launch.json to use these configurations.
Key debugging configurations include:
Each configuration sets up the appropriate ports, source maps, and debugging tools for a seamless development experience. You may need to adjust the ports and paths in the launch.json file to match your specific setup.
The system provides a tabbed interface for document processing and querying. Follow these steps in order:
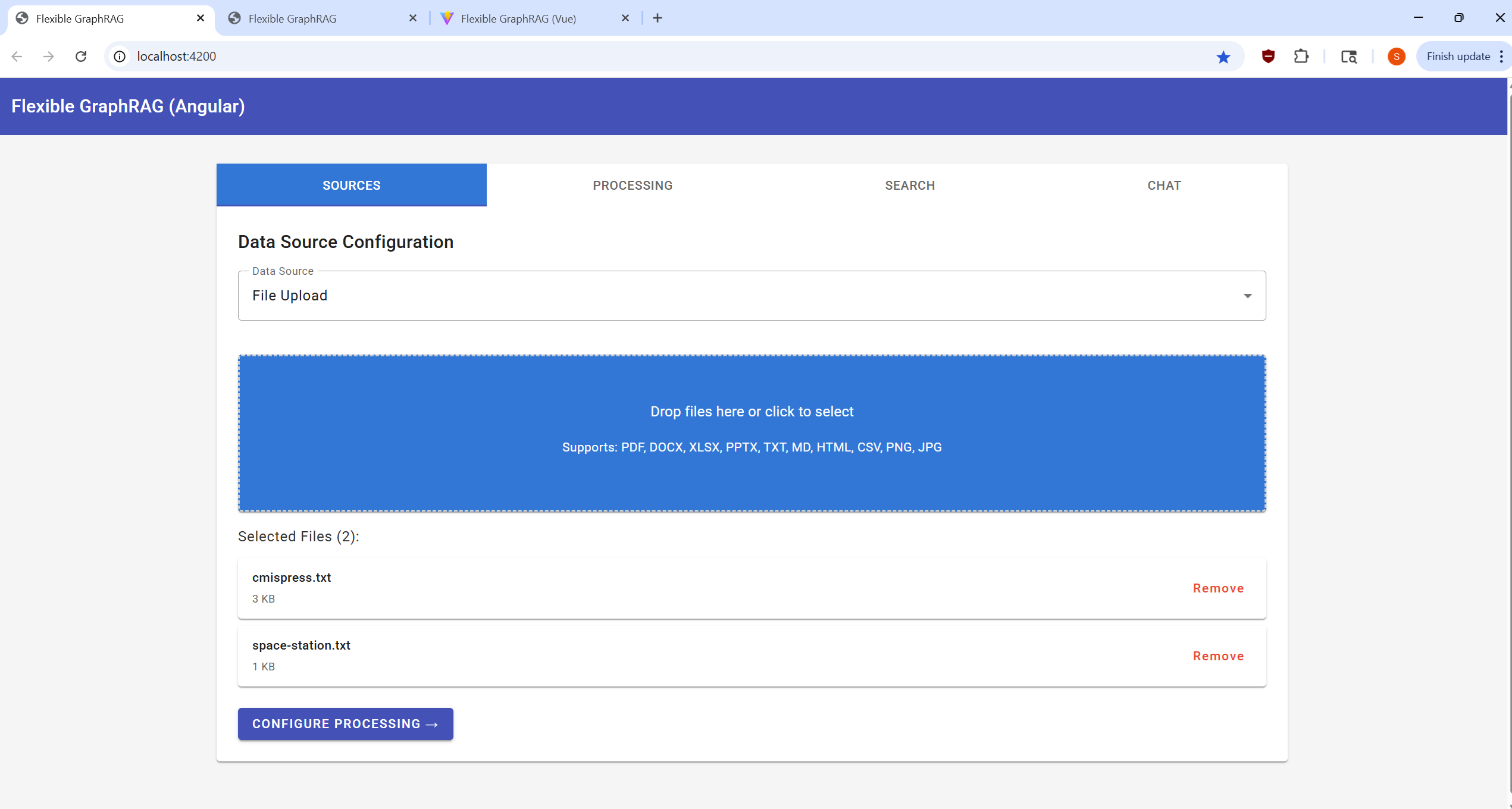
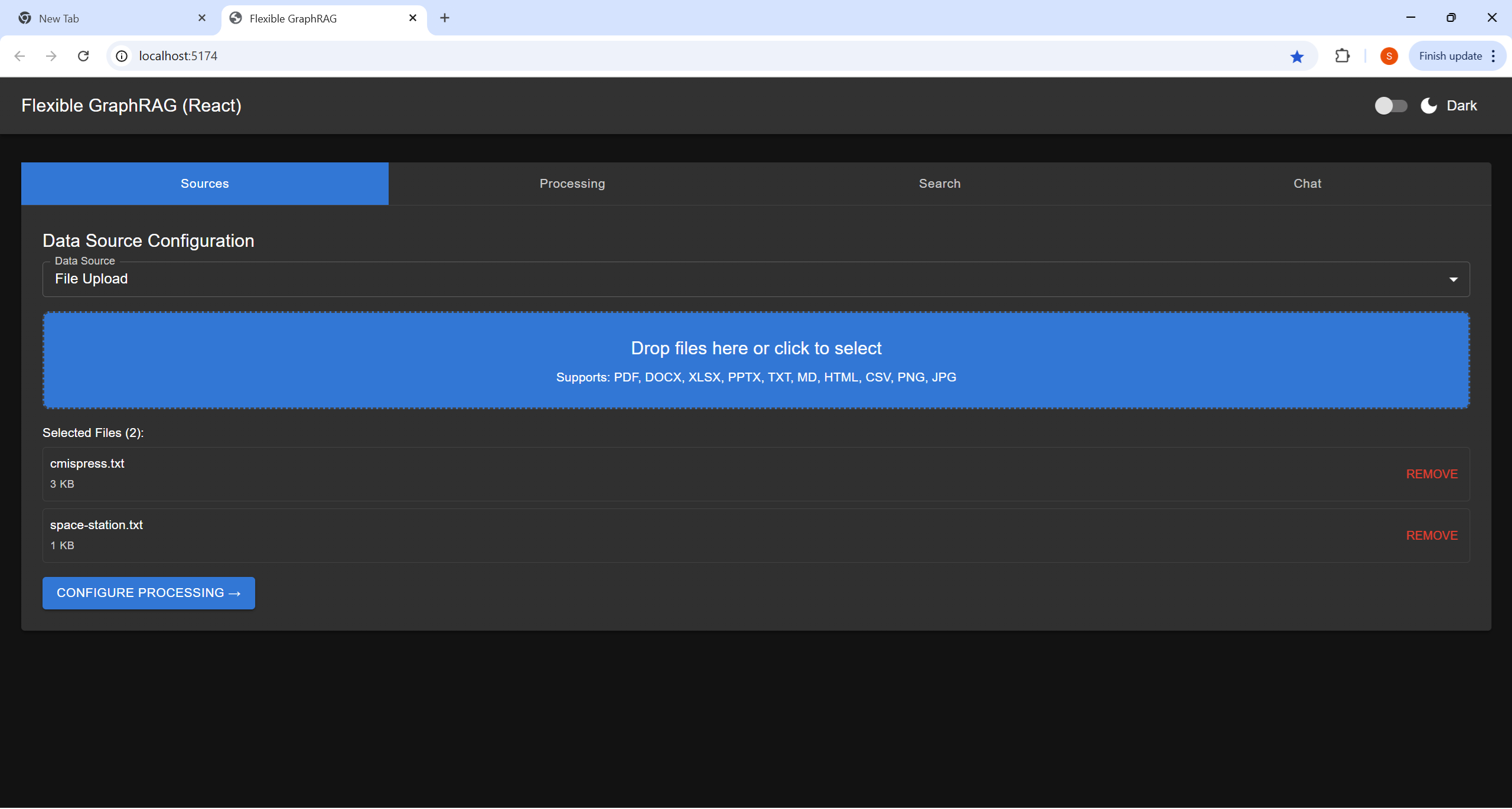
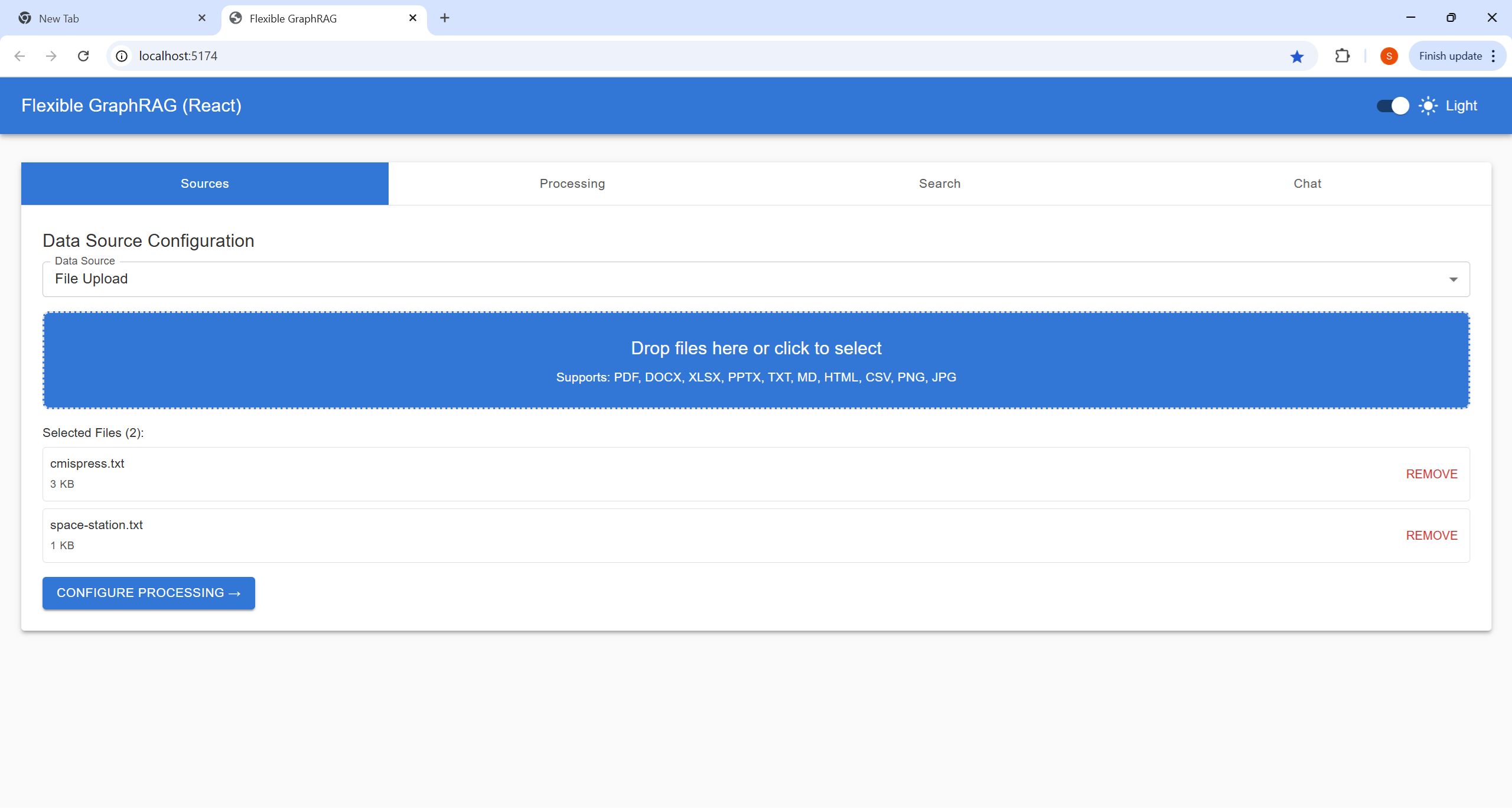
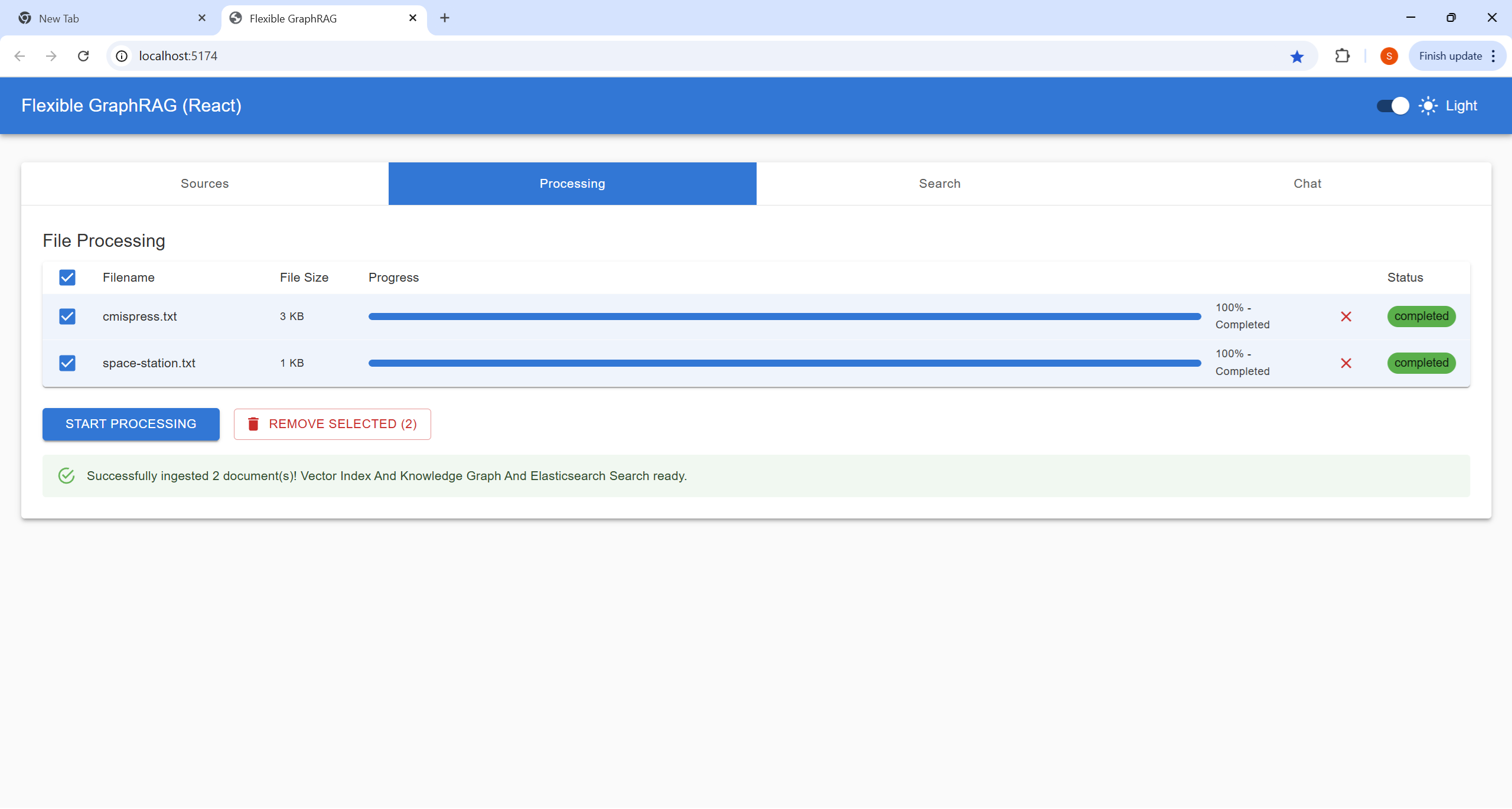
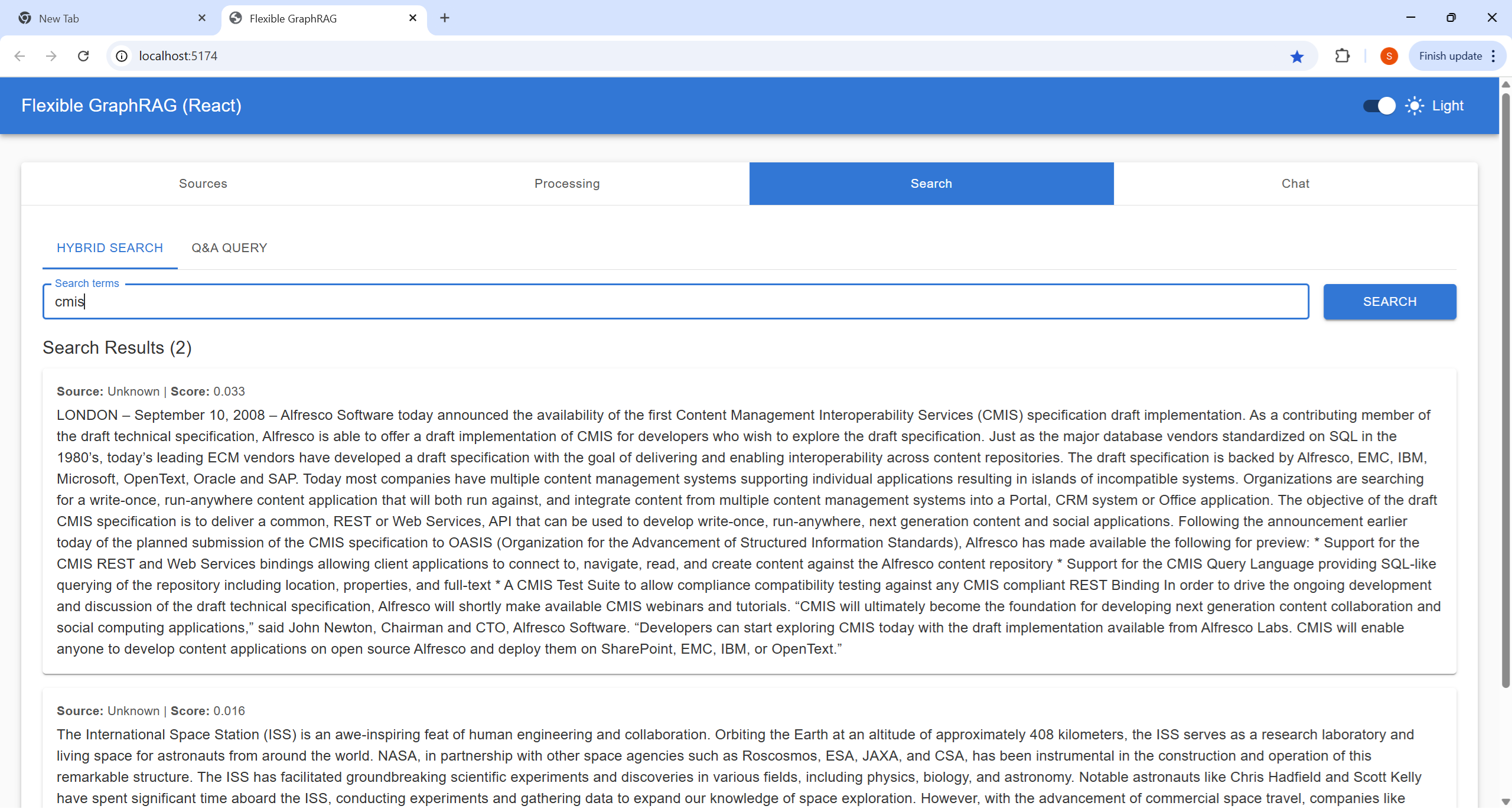
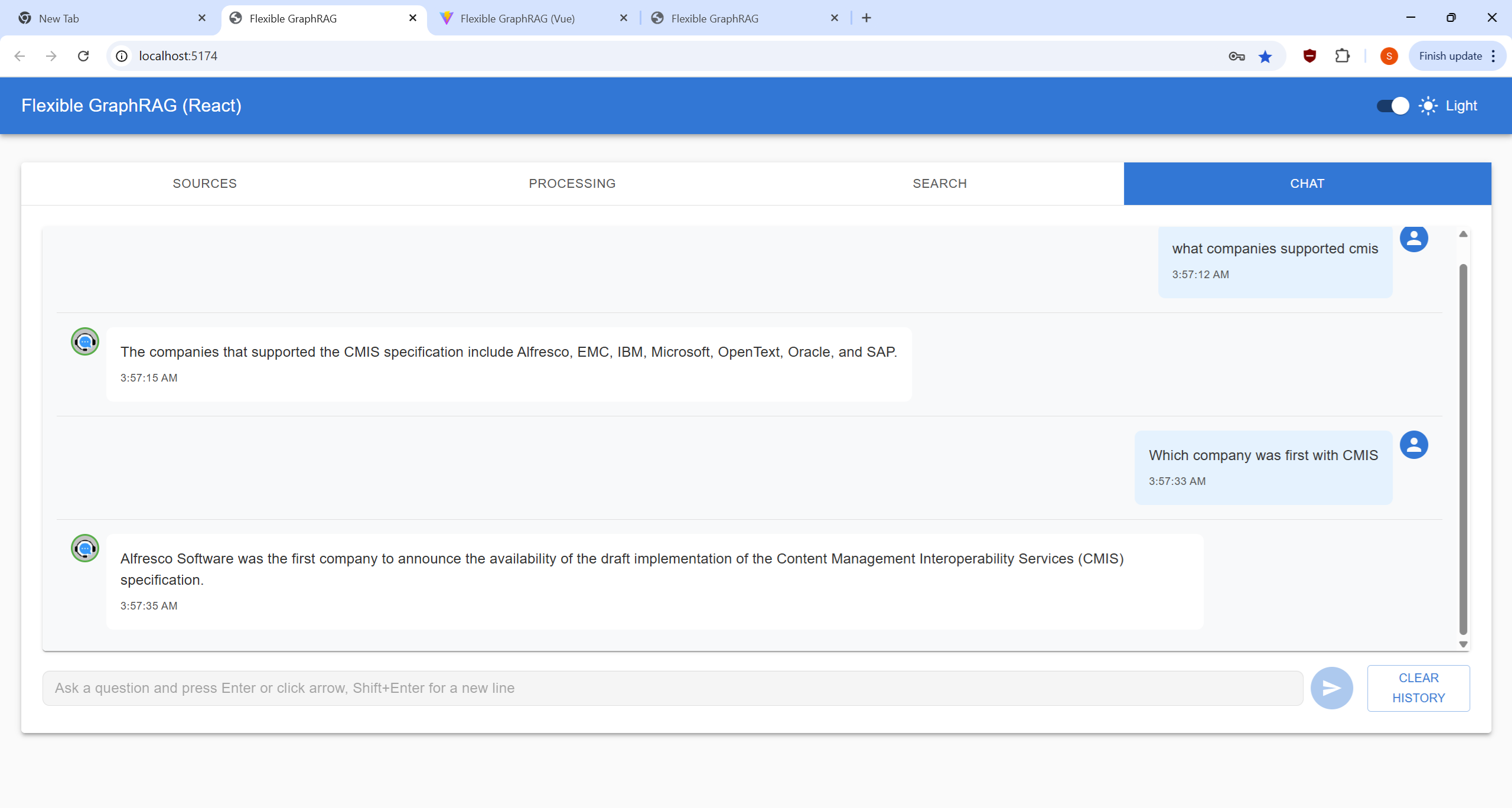
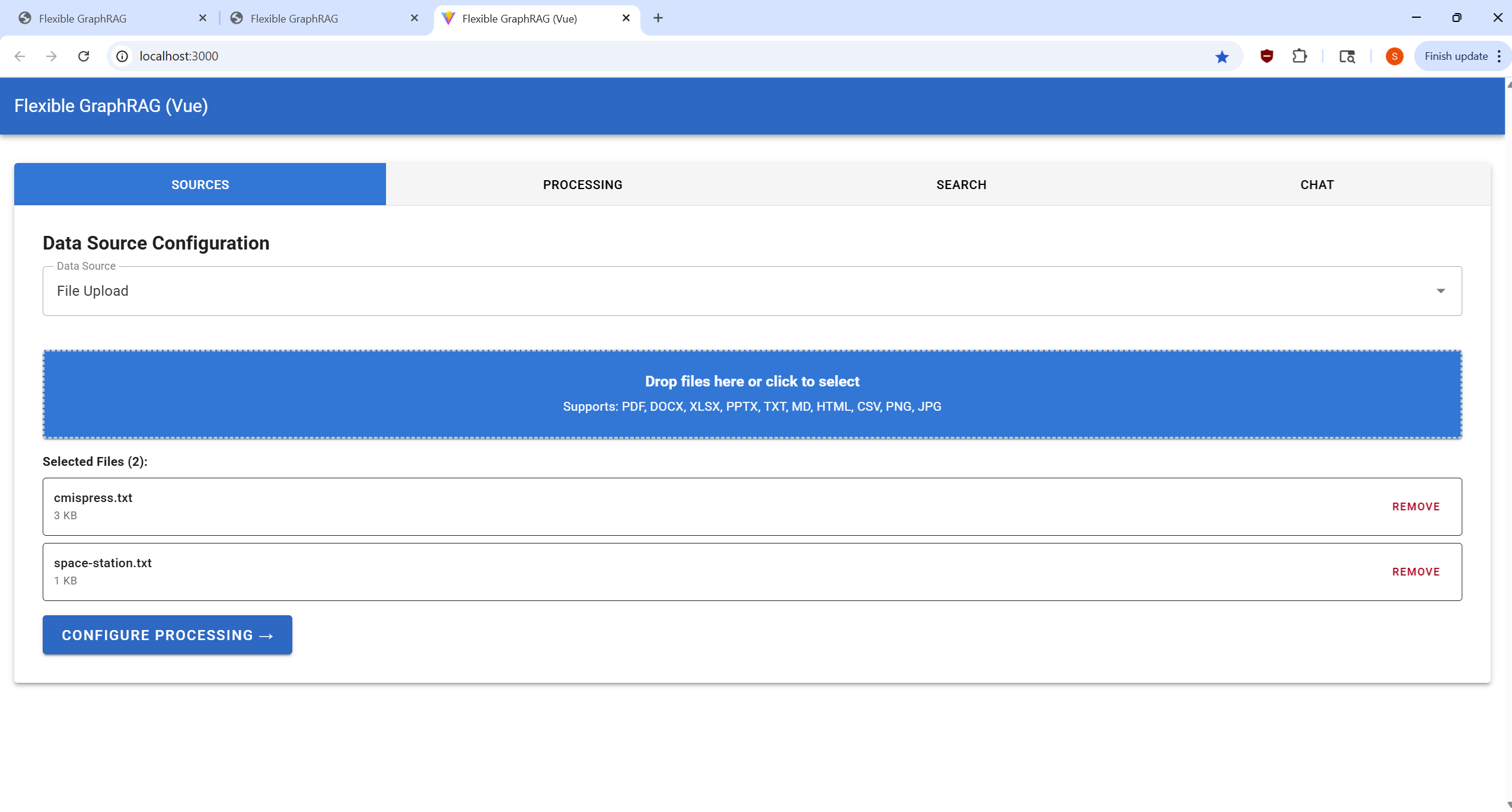
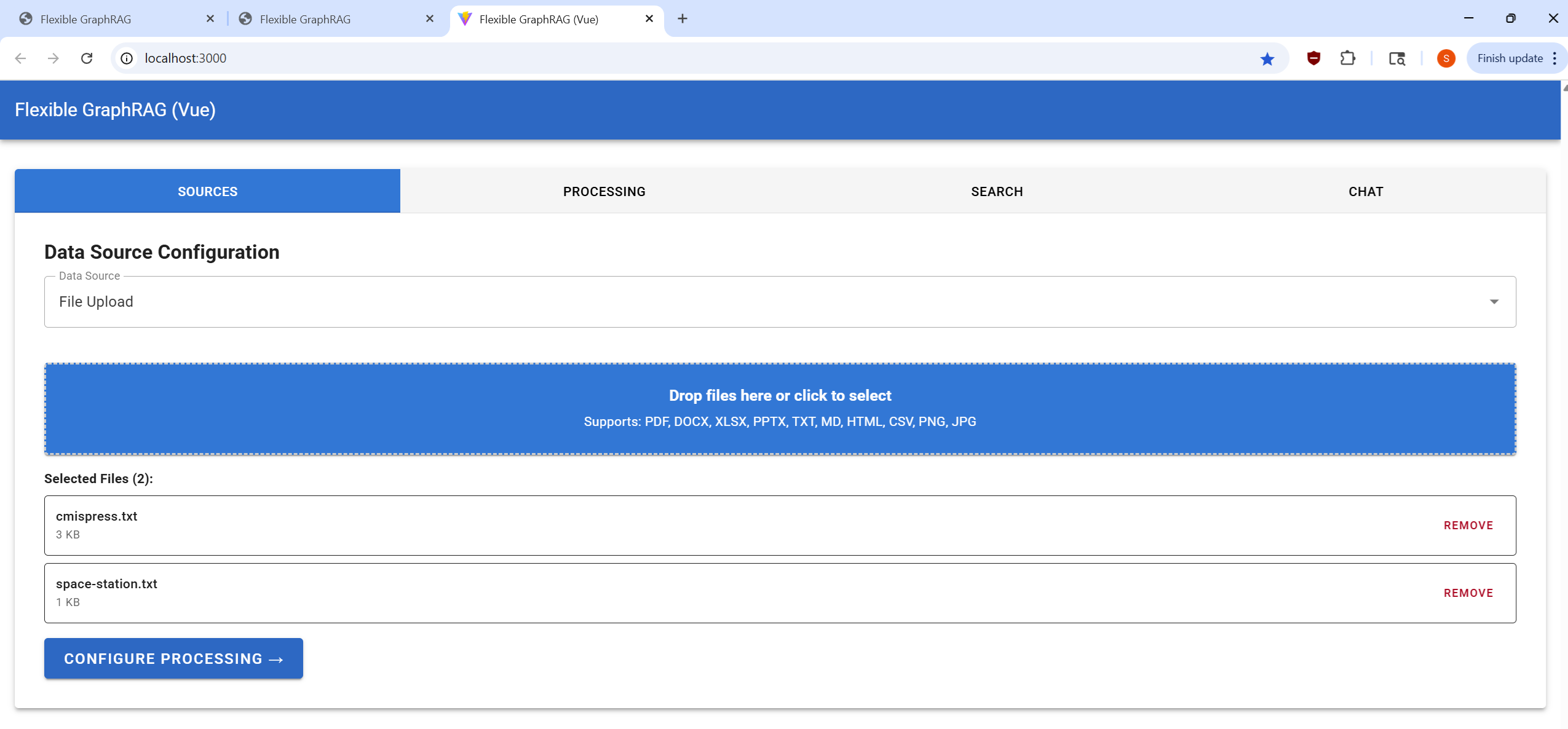
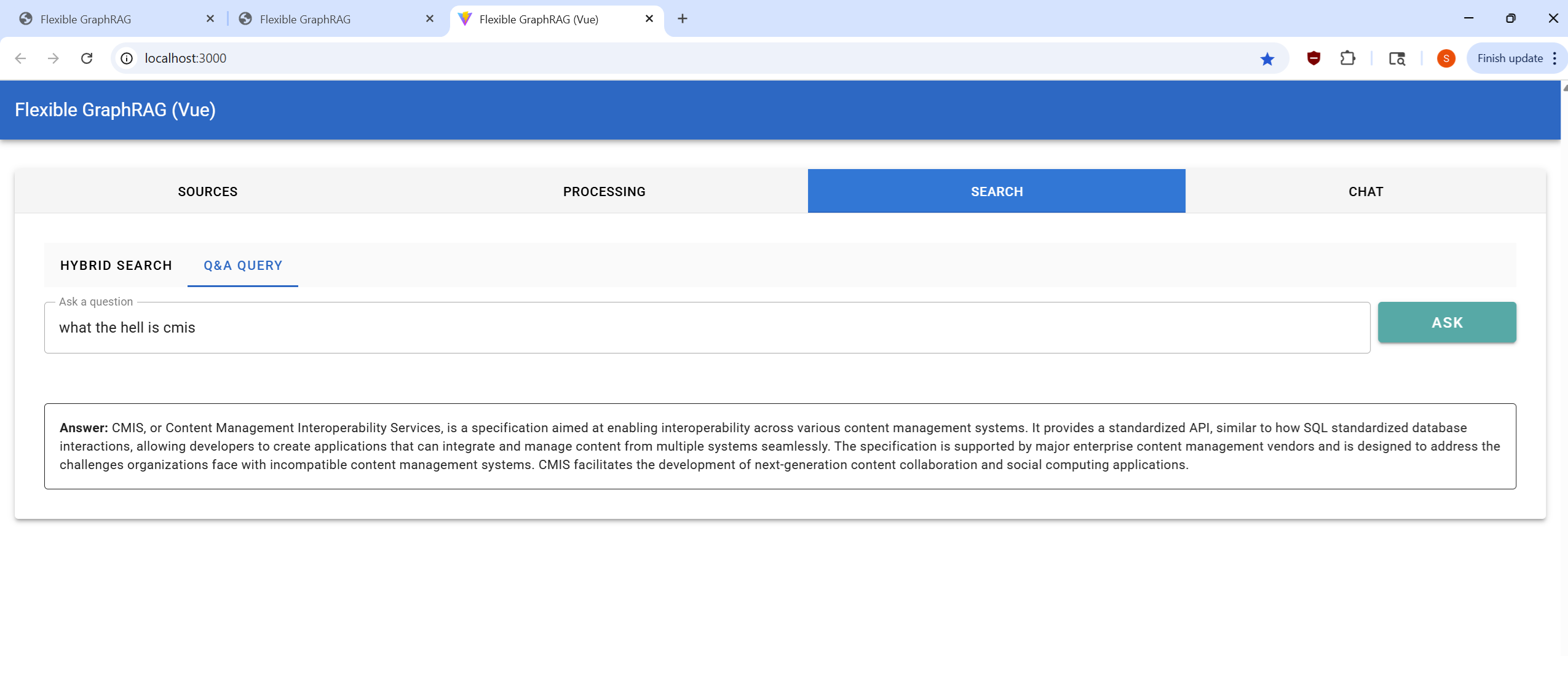
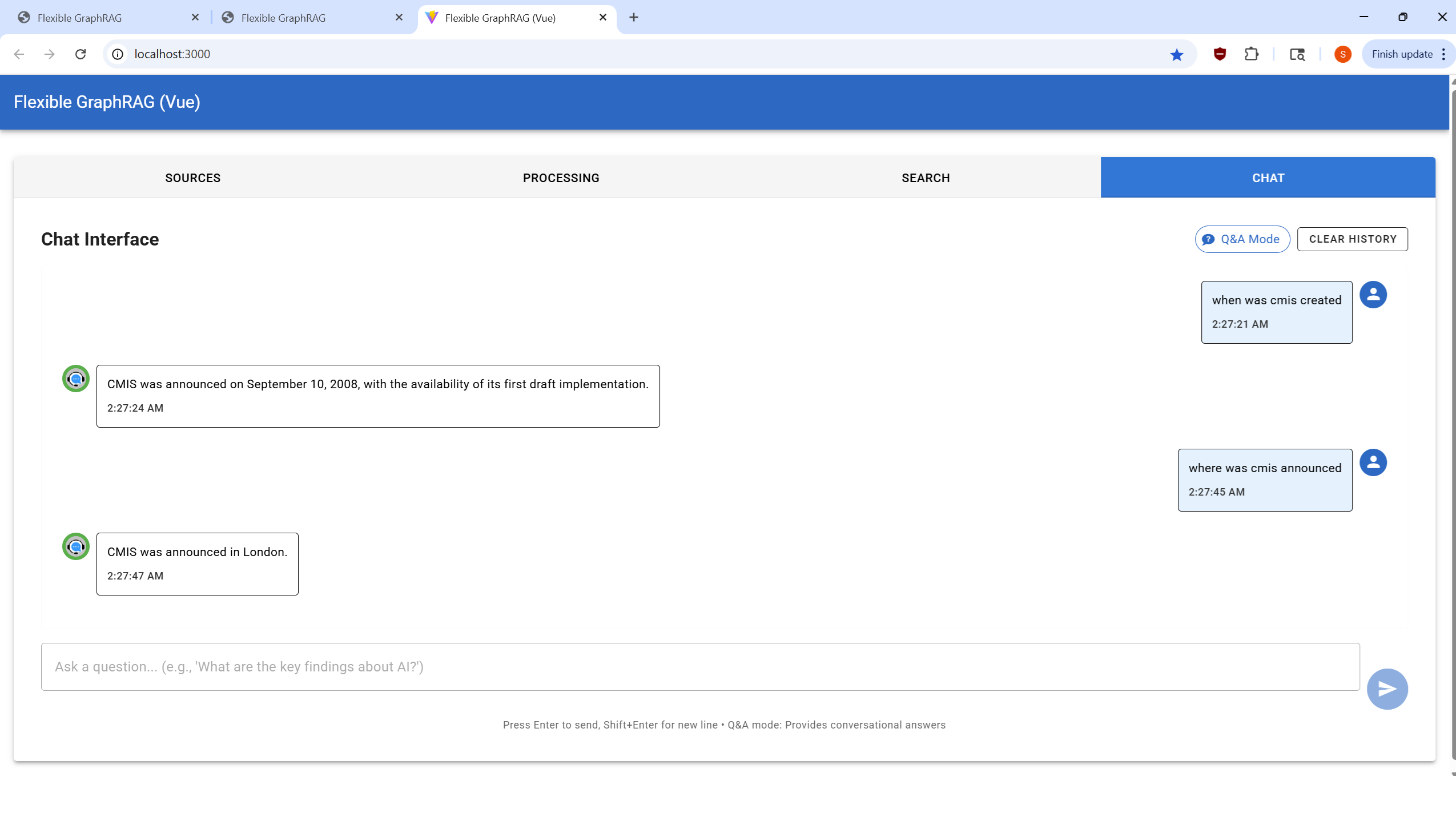
Configure your data source and select files for processing:
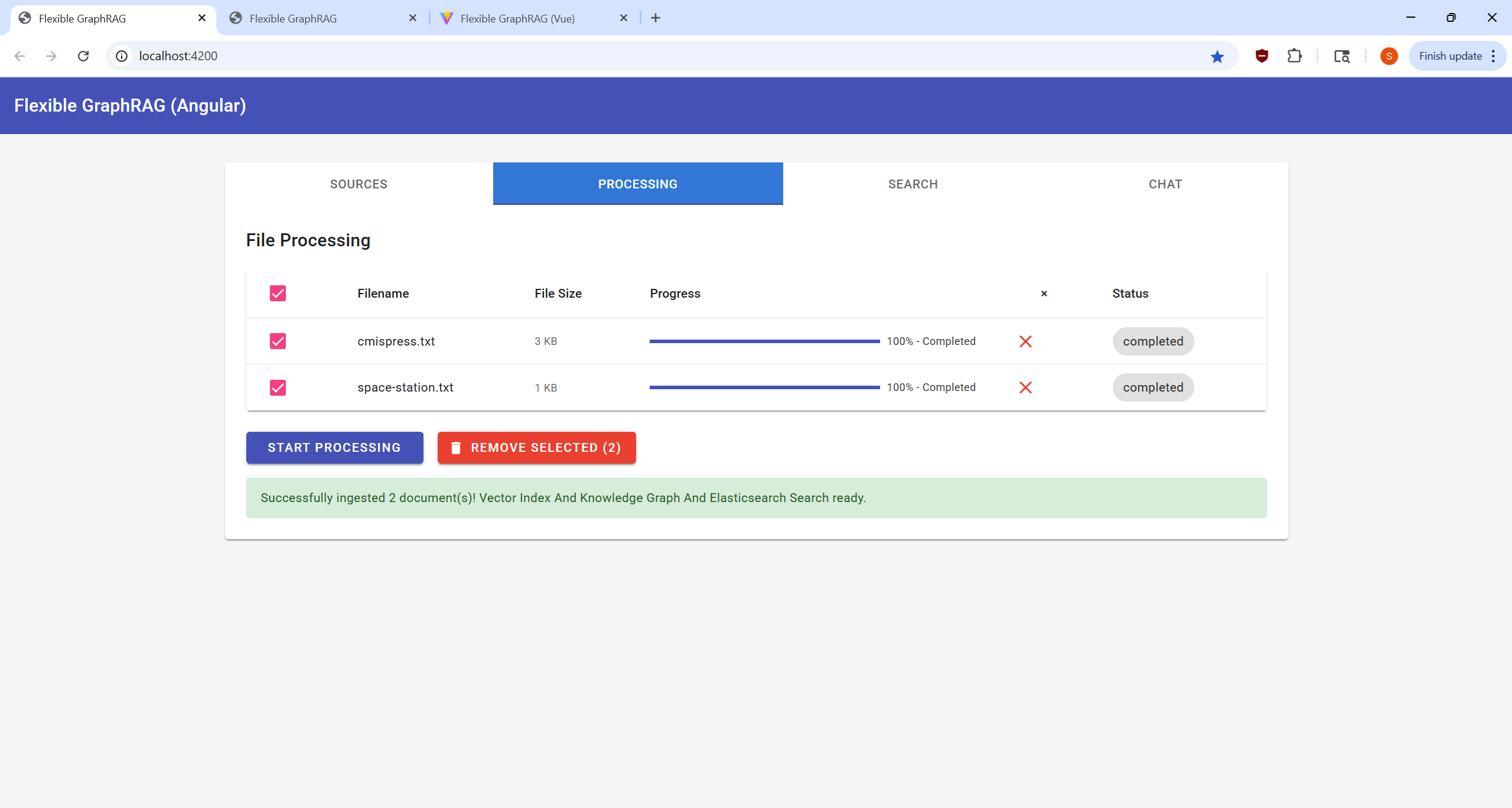
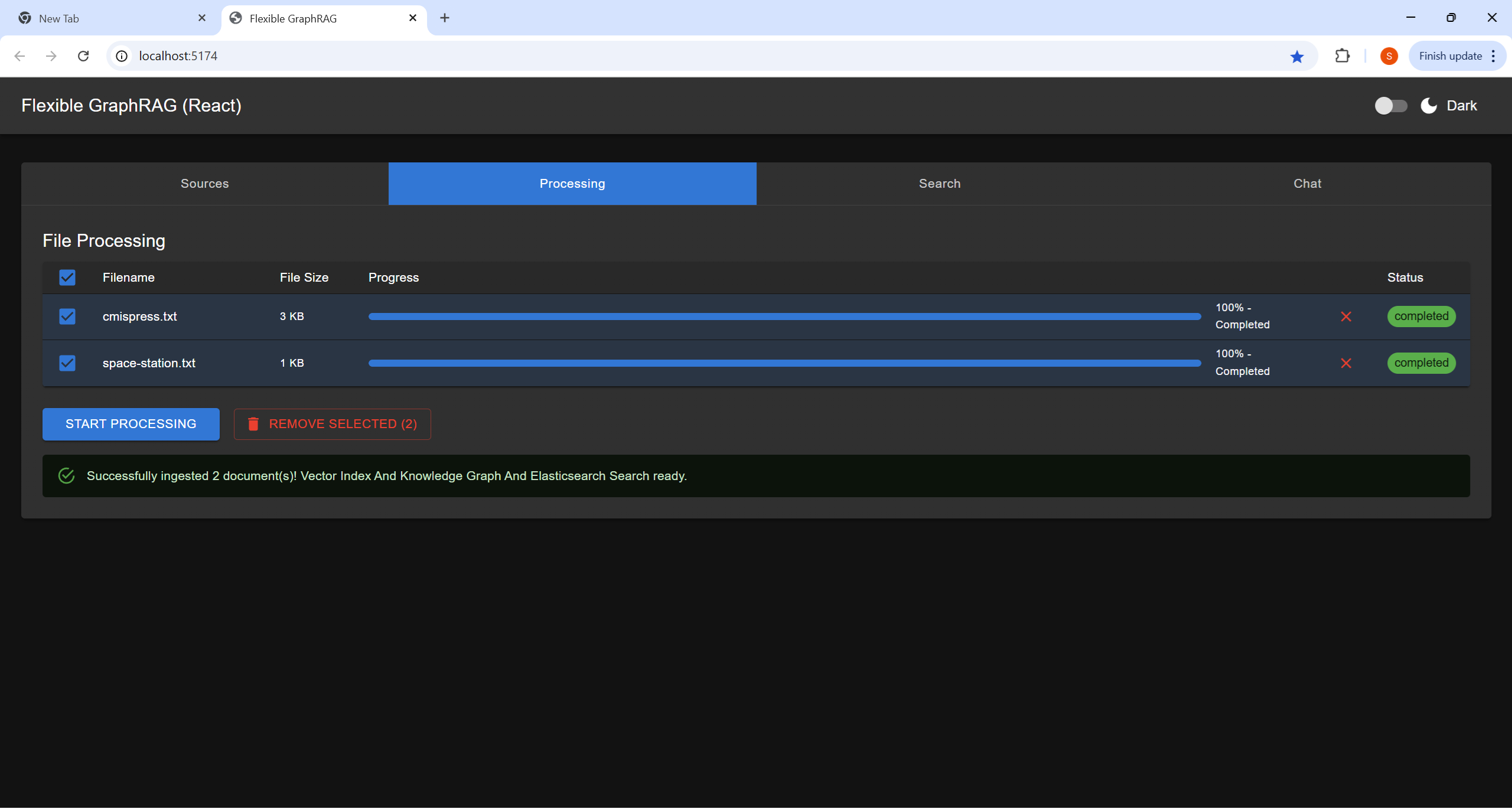
http://localhost:8080/alfresco)/Sites/example/documentLibrary)http://localhost:8080/alfresco/api/-default-/public/cmis/versions/1.1/atom)/Sites/example/documentLibrary)Process your selected documents and monitor progress:
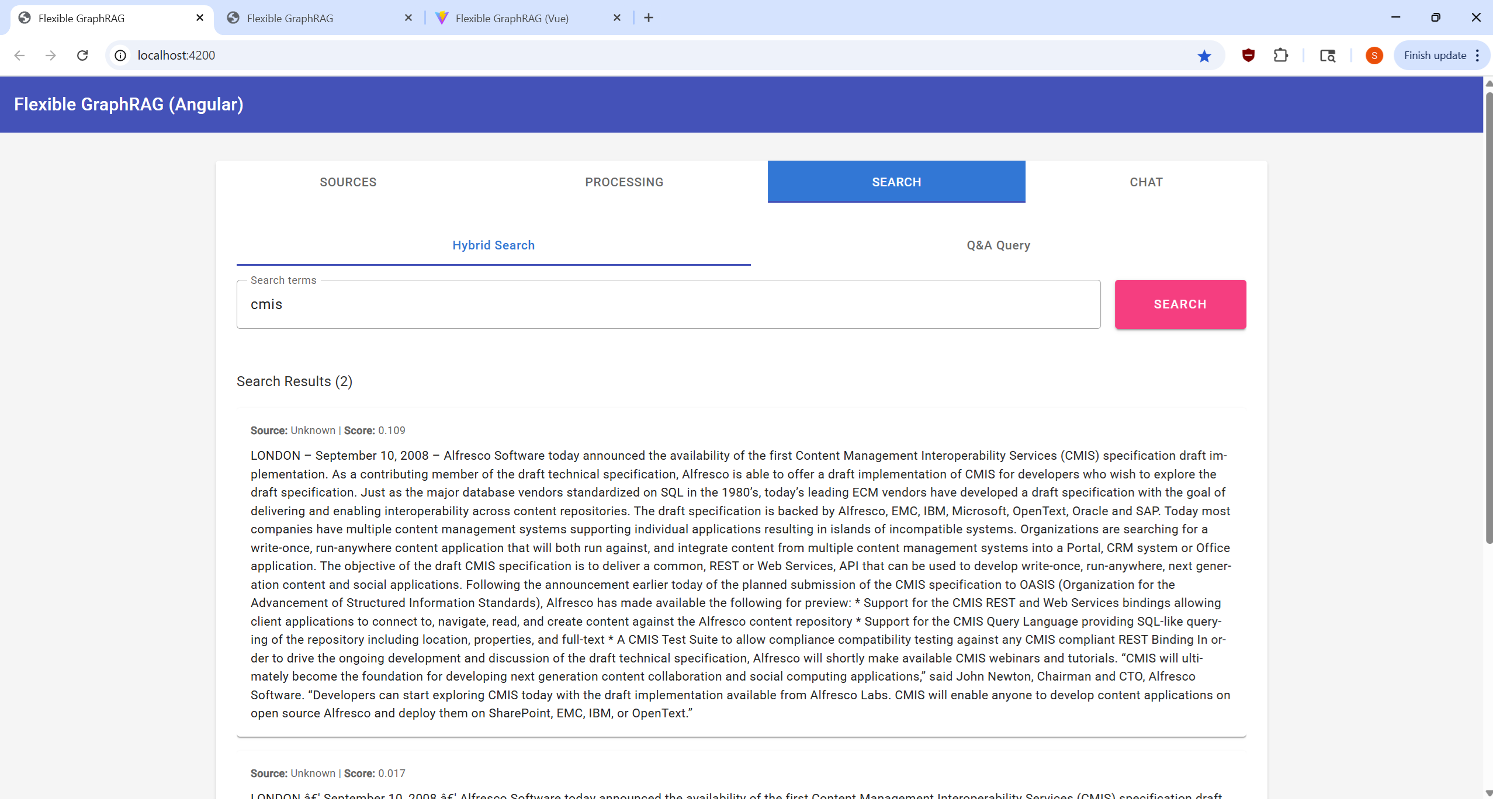
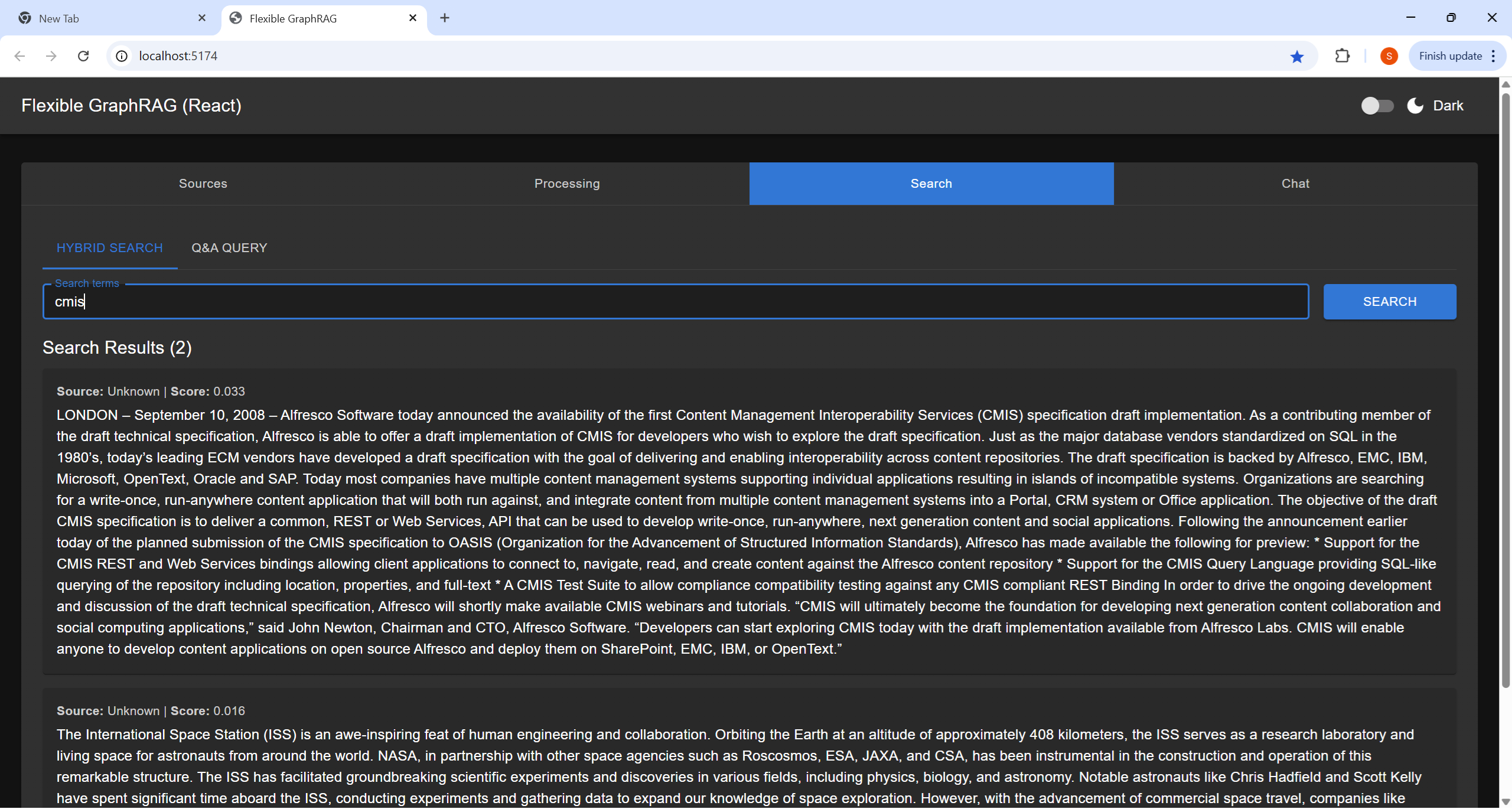
Perform searches on your processed documents:
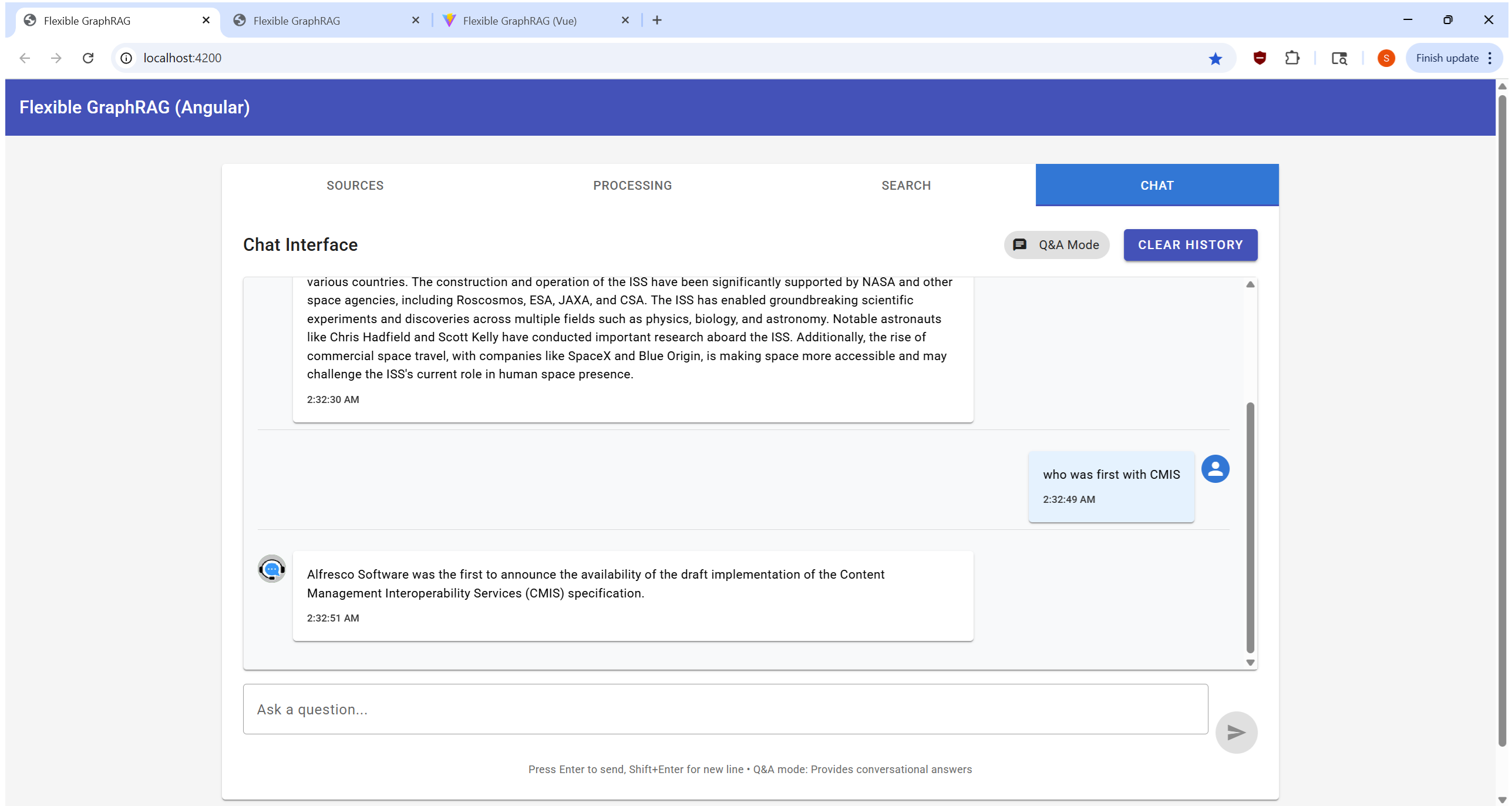
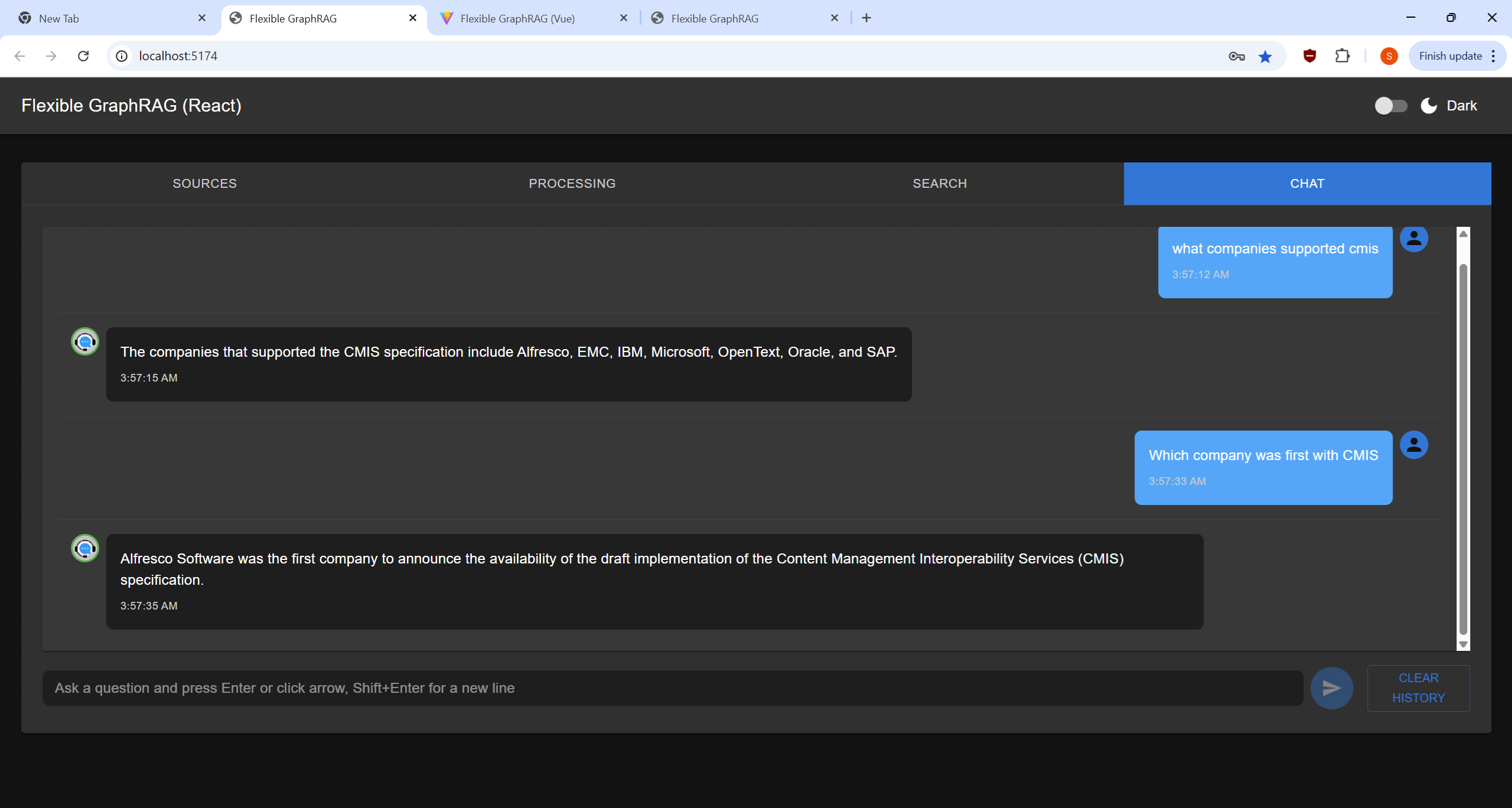
Interactive conversational interface for document Q&A:
The system combines three retrieval methods for comprehensive hybrid search:
How GraphRAG Works: The system extracts entities (people, organizations, concepts) and relationships from documents, stores them in a graph database, then uses graph traversal during retrieval to find not just direct matches but also related information through entity connections. This enables more comprehensive answers that incorporate contextual relationships between concepts.
Between tests you can clean up data:
/flexible-graphrag: Python FastAPI backend with LlamaIndex
main.py: FastAPI REST API server (clean, no MCP)backend.py: Shared business logic core used by both API and MCPconfig.py: Configurable settings for data sources, databases, and LLM providershybrid_system.py: Main hybrid search system using LlamaIndexdocument_processor.py: Document processing with Docling integrationfactories.py: Factory classes for LLM and database creationsources.py: Data source connectors (filesystem, CMIS, Alfresco)requirements.txt: FastAPI and LlamaIndex dependenciesstart.py: Startup script for uvicorninstall.py: Installation helper script/flexible-graphrag-mcp: Standalone FastMCP server
fastmcp-server.py: Proper remote MCP server using shared backend.pymain.py: Alternative HTTP-based MCP client (calls REST API)requirements.txt: FastMCP and shared backend dependenciesREADME.md: MCP server setup instructions/flexible-graphrag-ui: Frontend applications
/frontend-react: React + TypeScript frontend (built with Vite)
/src: Source codevite.config.ts: Vite configurationtsconfig.json: TypeScript configurationpackage.json: Node.js dependencies and scripts/frontend-angular: Angular + TypeScript frontend (built with Angular CLI)
/src: Source codeangular.json: Angular configurationtsconfig.json: TypeScript configurationpackage.json: Node.js dependencies and scripts/frontend-vue: Vue + TypeScript frontend (built with Vite)
/src: Source codevite.config.ts: Vite configurationtsconfig.json: TypeScript configurationpackage.json: Node.js dependencies and scripts/docker: Docker infrastructure
docker-compose.yaml: Main compose file with modular includes/includes: Modular database and service configurations/nginx: Reverse proxy configurationREADME.md: Docker deployment documentation/docs: Documentation
ENVIRONMENT-CONFIGURATION.md: Environment setup guideVECTOR-DIMENSIONS.md: Vector database cleanup instructionsSCHEMA-EXAMPLES.md: Knowledge graph schema examples/scripts: Utility scripts
create_opensearch_pipeline.py: OpenSearch hybrid search pipeline setupsetup-opensearch-pipeline.sh/.bat: Cross-platform pipeline creation/tests: Test suite
test_bm25_*.py: BM25 configuration and integration testsconftest.py: Test configuration and fixturesrun_tests.py: Test runnerThis project is licensed under the terms of the Apache License 2.0. See the LICENSE file for details.