
Apache Spark历史
STDIO连接AI代理到Spark历史服务器的MCP服务器
连接AI代理到Spark历史服务器的MCP服务器
![]()
![]()
![]()
![]()
![]()
![]()
🤖 Connect AI agents to Apache Spark History Server for intelligent job analysis and performance monitoring
Transform your Spark infrastructure monitoring with AI! This Model Context Protocol (MCP) server enables AI agents to analyze job performance, identify bottlenecks, and provide intelligent insights from your Spark History Server data.
Spark History Server MCP bridges AI agents with your existing Apache Spark infrastructure, enabling:
📺 See it in action:
graph TB A[🤖 AI Agent/LLM] --> F[📡 MCP Client] B[🦙 LlamaIndex Agent] --> F C[🌐 LangGraph] --> F D[�️ Claudep Desktop] --> F E[🛠️ Amazon Q CLI] --> F F --> G[⚡ Spark History MCP Server] G --> H[🔥 Prod Spark History Server] G --> I[🔥 Staging Spark History Server] G --> J[🔥 Dev Spark History Server] H --> K[📄 Prod Event Logs] I --> L[📄 Staging Event Logs] J --> M[📄 Dev Event Logs]
🔗 Components:
The package is published to PyPI: https://pypi.org/project/mcp-apache-spark-history-server/
git clone https://github.com/kubeflow/mcp-apache-spark-history-server.git cd mcp-apache-spark-history-server # Install Task (if not already installed) brew install go-task # macOS, see https://taskfile.dev/installation/ for others # Setup and start testing task start-spark-bg # Start Spark History Server with sample data (default Spark 3.5.5) # Or specify a different Spark version: # task start-spark-bg spark_version=3.5.2 task start-mcp-bg # Start MCP Server # Optional: Opens MCP Inspector on http://localhost:6274 for interactive testing # Requires Node.js: 22.7.5+ (Check https://github.com/modelcontextprotocol/inspector for latest requirements) task start-inspector-bg # Start MCP Inspector # When done, run `task stop-all`
If you just want to run the MCP server without cloning the repository:
# Run with uv without installing the module uvx --from mcp-apache-spark-history-server spark-mcp # OR run with pip and python. Use of venv is highly encouraged. python3 -m venv spark-mcp && source spark-mcp/bin/activate pip install mcp-apache-spark-history-server python3 -m spark_history_mcp.core.main # Deactivate venv deactivate
Edit config.yaml for your Spark History Server:
Config File Options:
--config /path/to/config.yaml or -c /path/to/config.yamlSHS_MCP_CONFIG=/path/to/config.yaml./config.yamlservers: local: default: true url: "http://your-spark-history-server:18080" auth: # optional username: "user" password: "pass" include_plan_description: false # optional, whether to include SQL execution plans by default (default: false) mcp: transports: - streamable-http # streamable-http or stdio. port: "18888" debug: true
The repository includes real Spark event logs for testing:
spark-bcec39f6201b42b9925124595baad260 - ✅ Successful ETL jobspark-110be3a8424d4a2789cb88134418217b - 🔄 Data processing jobspark-cc4d115f011443d787f03a71a476a745 - 📈 Multi-stage analytics jobSee TESTING.md for using them.
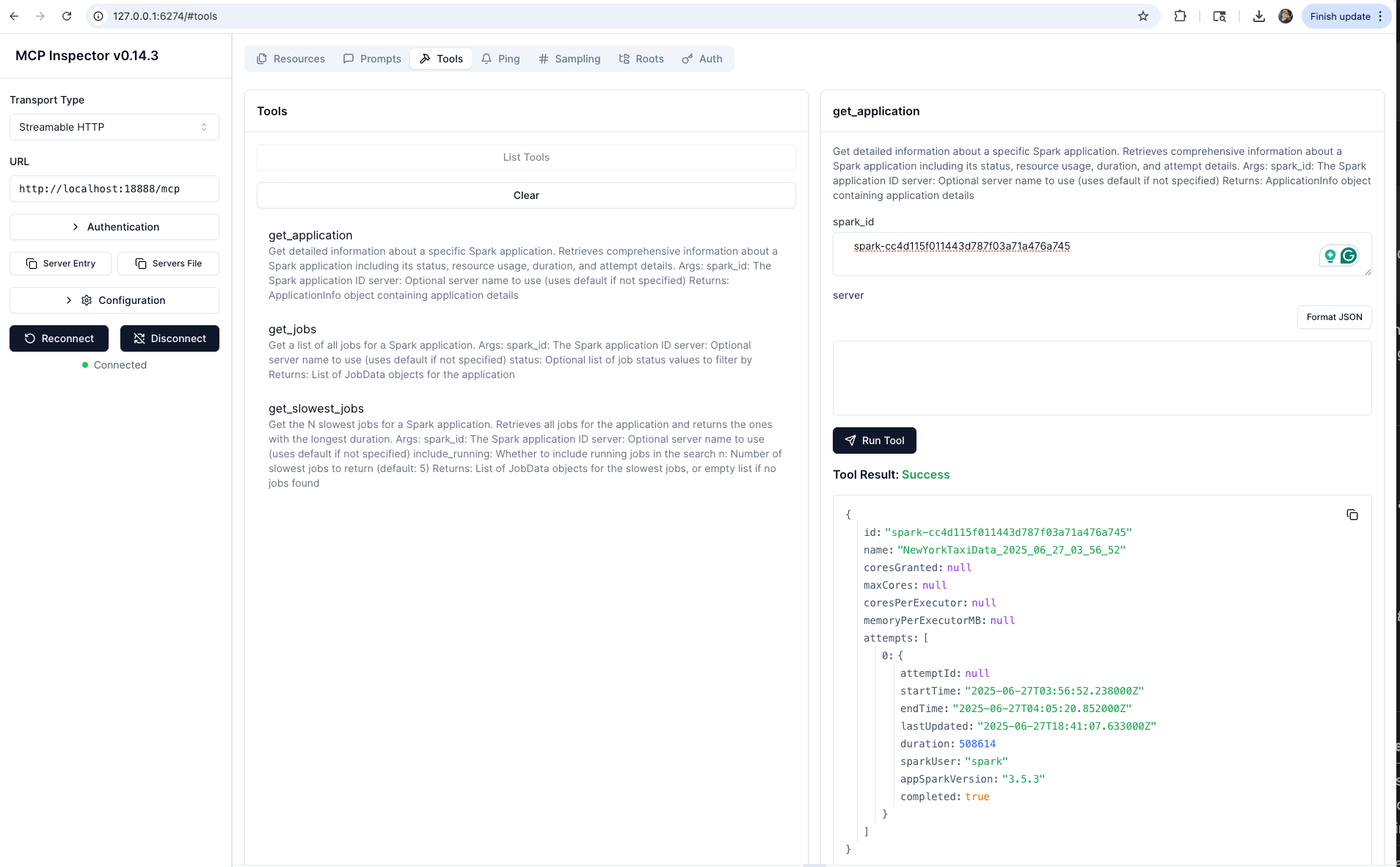
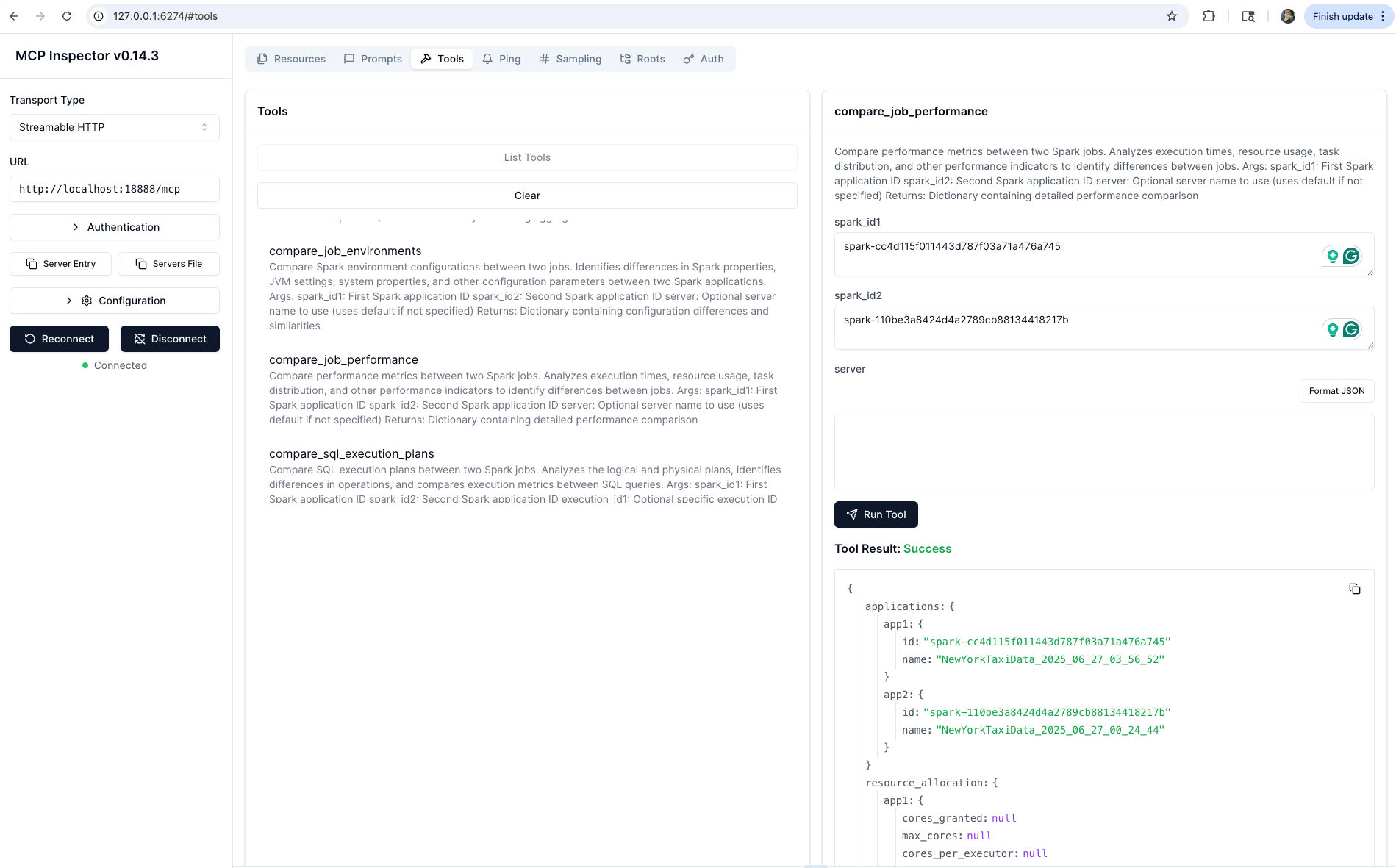
Note: These tools are subject to change as we scale and improve the performance of the MCP server.
The MCP server provides 18 specialized tools organized by analysis patterns. LLMs can intelligently select and combine these tools based on user queries:
Basic application metadata and overview
| 🔧 Tool | 📝 Description |
|---|---|
list_applications | 📋 Get a list of all applications available on the Spark History Server with optional filtering by status, date ranges, and limits |
get_application | 📊 Get detailed information about a specific Spark application including status, resource usage, duration, and attempt details |
Job-level performance analysis and identification
| 🔧 Tool | 📝 Description |
|---|---|
list_jobs | 🔗 Get a list of all jobs for a Spark application with optional status filtering |
list_slowest_jobs | ⏱️ Get the N slowest jobs for a Spark application (excludes running jobs by default) |
Stage-level performance deep dive and task metrics
| 🔧 Tool | 📝 Description |
|---|---|
list_stages | ⚡ Get a list of all stages for a Spark application with optional status filtering and summaries |
list_slowest_stages | 🐌 Get the N slowest stages for a Spark application (excludes running stages by default) |
get_stage | 🎯 Get information about a specific stage with optional attempt ID and summary metrics |
get_stage_task_summary | 📊 Get statistical distributions of task metrics for a specific stage (execution times, memory usage, I/O metrics) |
Resource utilization, executor performance, and allocation tracking
| 🔧 Tool | 📝 Description |
|---|---|
list_executors | 🖥️ Get executor information with optional inactive executor inclusion |
get_executor | 🔍 Get information about a specific executor including resource allocation, task statistics, and performance metrics |
get_executor_summary | 📈 Aggregates metrics across all executors (memory usage, disk usage, task counts, performance metrics) |
get_resource_usage_timeline | 📅 Get chronological view of resource allocation and usage patterns including executor additions/removals |
Spark configuration, environment variables, and runtime settings
| 🔧 Tool | 📝 Description |
|---|---|
get_environment | ⚙️ Get comprehensive Spark runtime configuration including JVM info, Spark properties, system properties, and classpath |
SQL performance analysis and execution plan comparison
| 🔧 Tool | 📝 Description |
|---|---|
list_slowest_sql_queries | 🐌 Get the top N slowest SQL queries for an application with detailed execution metrics and optional plan descriptions |
compare_sql_execution_plans | 🔍 Compare SQL execution plans between two Spark jobs, analyzing logical/physical plans and execution metrics |
Intelligent bottleneck identification and performance recommendations
| 🔧 Tool | 📝 Description |
|---|---|
get_job_bottlenecks | 🚨 Identify performance bottlenecks by analyzing stages, tasks, and executors with actionable recommendations |
Cross-application comparison for regression detection and optimization
| 🔧 Tool | 📝 Description |
|---|---|
compare_job_environments | ⚙️ Compare Spark environment configurations between two jobs to identify differences in properties and settings |
compare_job_performance | 📈 Compare performance metrics between two Spark jobs including execution times, resource usage, and task distribution |
Query Pattern Examples:
list_applicationsget_job_bottlenecks + list_slowest_stages + get_executor_summarycompare_job_performance + compare_job_environmentsget_stage + get_stage_task_summaryget_resource_usage_timeline + get_executor_summarylist_slowest_sql_queries + compare_sql_execution_plansIf you are an existing AWS user looking to analyze your Spark Applications, we provide detailed setup guides for:
These guides provide step-by-step instructions for setting up the Spark History Server MCP with your AWS services.
Deploy using Kubernetes with Helm:
⚠️ Work in Progress: We are still testing and will soon publish the container image and Helm registry to GitHub for easy deployment.
# 📦 Deploy with Helm helm install spark-history-mcp ./deploy/kubernetes/helm/spark-history-mcp/ # 🎯 Production configuration helm install spark-history-mcp ./deploy/kubernetes/helm/spark-history-mcp/ \ --set replicaCount=3 \ --set autoscaling.enabled=true \ --set monitoring.enabled=true
📚 See deploy/kubernetes/helm/ for complete deployment manifests and configuration options.
Note: When using Secret Store CSI Driver authentication, you must create a
SecretProviderClassexternally before deploying the chart.
Setup multiple Spark history servers in the config.yaml and choose which server you want the LLM to interact with for each query.
servers: production: default: true url: "http://prod-spark-history:18080" auth: username: "user" password: "pass" staging: url: "http://staging-spark-history:18080"
💁 User Query: "Can you get application <app_id> using production server?"
🤖 AI Tool Request:
{ "app_id": "<app_id>", "server": "production" }
🤖 AI Tool Response:
{ "id": "<app_id>>", "name": "app_name", "coresGranted": null, "maxCores": null, "coresPerExecutor": null, "memoryPerExecutorMB": null, "attempts": [ { "attemptId": null, "startTime": "2023-09-06T04:44:37.006000Z", "endTime": "2023-09-06T04:45:40.431000Z", "lastUpdated": "2023-09-06T04:45:42Z", "duration": 63425, "sparkUser": "spark", "appSparkVersion": "3.3.0", "completed": true } ] }
SHS_MCP_PORT - Port for MCP server (default: 18888)
SHS_MCP_DEBUG - Enable debug mode (default: false)
SHS_MCP_ADDRESS - Address for MCP server (default: localhost)
SHS_MCP_TRANSPORT - MCP transport mode (default: streamable-http)
SHS_SERVERS_*_URL - URL for a specific server
SHS_SERVERS_*_AUTH_USERNAME - Username for a specific server
SHS_SERVERS_*_AUTH_PASSWORD - Password for a specific server
SHS_SERVERS_*_AUTH_TOKEN - Token for a specific server
SHS_SERVERS_*_VERIFY_SSL - Whether to verify SSL for a specific server (true/false)
SHS_SERVERS_*_TIMEOUT - HTTP request timeout in seconds for a specific server (default: 30)
SHS_SERVERS_*_EMR_CLUSTER_ARN - EMR cluster ARN for a specific server
SHS_SERVERS_*_INCLUDE_PLAN_DESCRIPTION - Whether to include SQL execution plans by default for a specific server (true/false, default: false)
| Integration | Transport | Best For |
|---|---|---|
| Local Testing | HTTP | Development, testing tools |
| Claude Desktop | STDIO | Interactive analysis |
| Amazon Q CLI | STDIO | Command-line automation |
| Kiro | HTTP | IDE integration, code-centric analysis |
| LangGraph | HTTP | Multi-agent workflows |
| Strands Agents | HTTP | Multi-agent workflows |
🤖 AI Query: "Why is my ETL job running slower than usual?"
📊 MCP Actions:
✅ Analyze application metrics
✅ Compare with historical performance
✅ Identify bottleneck stages
✅ Generate optimization recommendations
🤖 AI Query: "What caused job 42 to fail?"
🔍 MCP Actions:
✅ Examine failed tasks and error messages
✅ Review executor logs and resource usage
✅ Identify root cause and suggest fixes
🤖 AI Query: "Compare today's batch job with yesterday's run"
📊 MCP Actions:
✅ Compare execution times and resource usage
✅ Identify performance deltas
✅ Highlight configuration differences
Check CONTRIBUTING.md for full guidelines on contributions
Apache License 2.0 - see LICENSE file for details.
This project is built for use with Apache Spark™ History Server. Not affiliated with or endorsed by the Apache Software Foundation.
🔥 Connect your Spark infrastructure to AI agents
🚀 Get Started | 🛠️ View Tools | 🧪 Test Now | 🤝 Contribute
Built by the community, for the community 💙