
OpenCV
STDIOOpenCV computer vision server with image processing, object detection and video analysis capabilities.
OpenCV computer vision server with image processing, object detection and video analysis capabilities.
MCP server providing powerful OpenCV computer vision capabilities for AI assistants.
OpenCV MCP Server is a Python package that provides OpenCV's image and video processing capabilities through the Model Context Protocol (MCP). This allows AI assistants and language models to access powerful computer vision tools for tasks ranging from basic image manipulation to advanced object detection and tracking.
With OpenCV MCP Server, AI systems can:


 Example of contour detection processing applied to the original video above
Example of contour detection processing applied to the original video above
pip install opencv-mcp-server
For development:
# Clone the repository git clone https://github.com/yourusername/opencv-mcp-server.git cd opencv-mcp-server # Create a virtual environment python -m venv .venv source .venv/bin/activate # On Windows: .venv\Scripts\activate # Install dependencies pip install -e .
Add to your Claude Desktop configuration:
{ "mcpServers": { "opencv": { "command": "uvx", "args": [ "opencv-mcp-server" ] } } }
Install uvx
brew install uv
Then restart Claude Desktop
from opencv_mcp_server import opencv_client # Initialize client client = opencv_client.OpenCVClient() # Use tools result = client.resize_image( image_path="input.jpg", width=800, height=600 )
Since all required models are already configured in the OPENCV_DNN_MODELS_DIR, you can use object detection without specifying model paths:
# Detect objects using pre-configured YOLO model result = detect_objects_tool( image_path="street.jpg", confidence_threshold=0.5, nms_threshold=0.4 )
The server can be configured using environment variables:
MCP_TRANSPORT: Transport method (default: "stdio")OPENCV_DNN_MODELS_DIR: Directory for storing DNN models (default: "models")CV_HAAR_CASCADE_DIR: Directory for storing Haar cascade files (optional)The computer vision and object detection tools require pre-trained models to function properly. These models should be placed in the directory specified by the OPENCV_DNN_MODELS_DIR environment variable (default: "./models").
The following models have been pre-configured:
Face Detection (DNN method)
deploy.prototxt - Face detection configurationres10_300x300_ssd_iter_140000.caffemodel - Face detection model weightsObject Detection (YOLO)
yolov3.weights - YOLO model weightsyolov3.cfg - YOLO configuration filecoco.names - Class names for detected objectsdetect_faces_tool uses the DNN models when method="dnn" is specifieddetect_objects_tool uses the YOLO models for general object detectionFor those who need to download these models, see the "Installation" section or visit:
The OpenCV MCP Server provides a wide range of computer vision tools organized into four categories:
These tools provide fundamental image manipulation capabilities:
save_image_tool: Save an image to a file
path_in (input image path), path_out (output file path)save_image_tool(path_in="processed.jpg", path_out="final.jpg")convert_color_space_tool: Convert image between color spaces (BGR, RGB, GRAY, HSV, etc.)
image_path, source_space, target_spaceconvert_color_space_tool(image_path="image.jpg", source_space="BGR", target_space="HSV")resize_image_tool: Resize an image to specific dimensions
image_path, width, height, interpolation (optional)resize_image_tool(image_path="large.jpg", width=800, height=600)crop_image_tool: Crop a region from an image
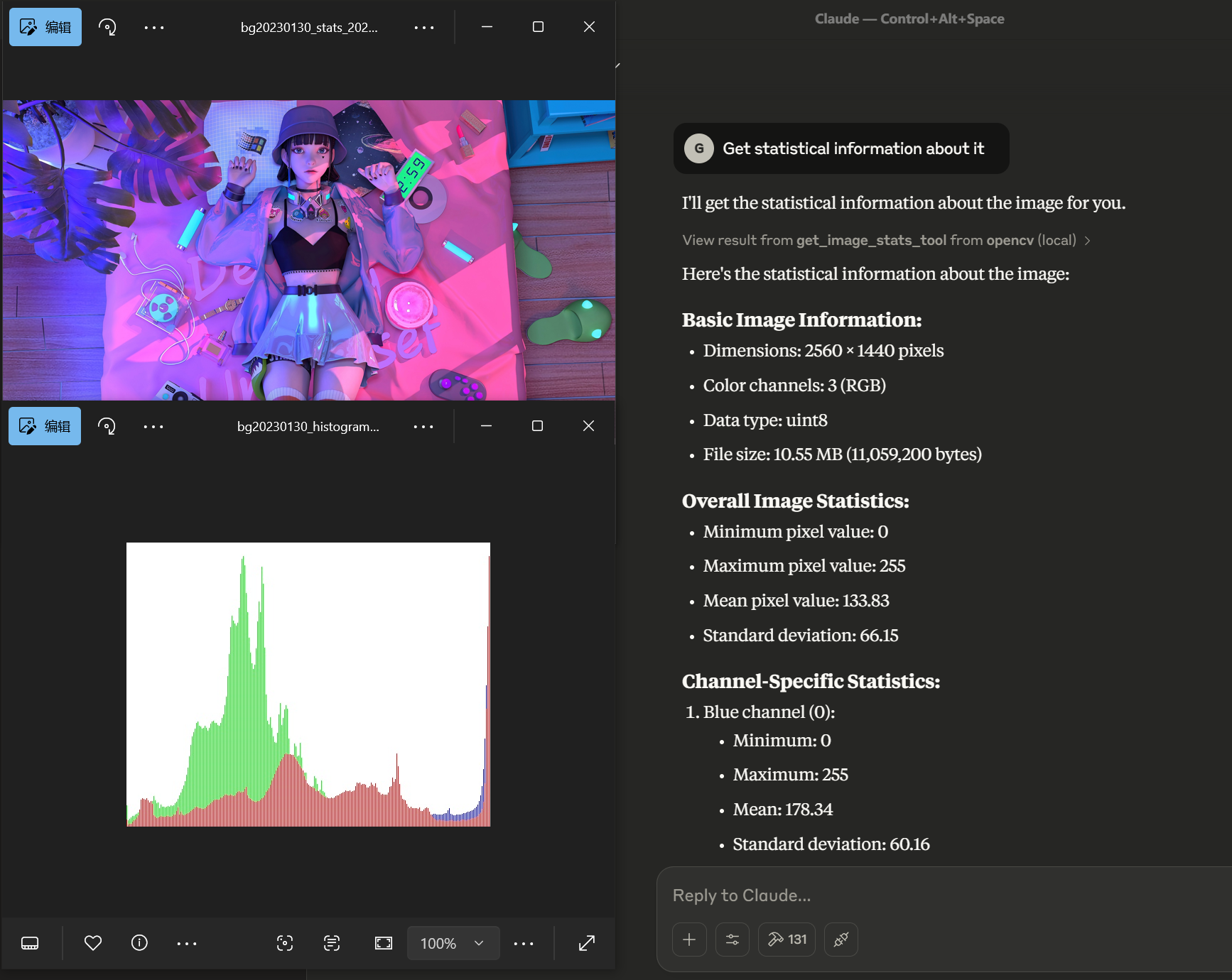
image_path, x, y, width, heightcrop_image_tool(image_path="scene.jpg", x=100, y=150, width=300, height=200)get_image_stats_tool: Get statistical information about an image
image_path, channels (boolean, default: true)get_image_stats_tool(image_path="photo.jpg", channels=True)These tools provide advanced image processing and transformation capabilities:
apply_filter_tool: Apply various filters to an image (blur, gaussian, median, bilateral)
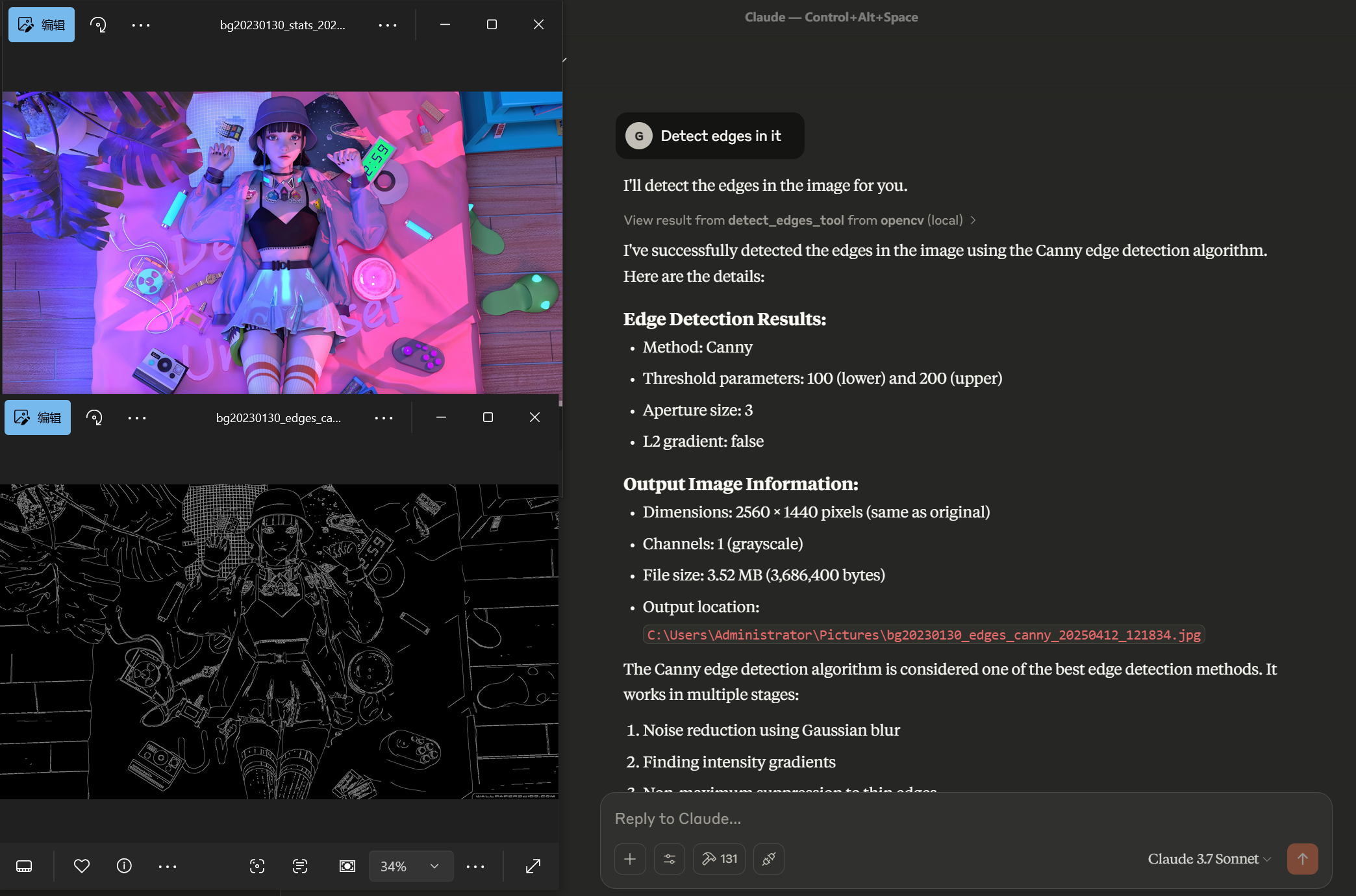
image_path, filter_type, kernel_size, and filter-specific parametersapply_filter_tool(image_path="noisy.jpg", filter_type="gaussian", kernel_size=5)detect_edges_tool: Detect edges in an image using different methods (Canny, Sobel, Laplacian, Scharr)
image_path, method, threshold parameters, and method-specific parametersdetect_edges_tool(image_path="objects.jpg", method="canny", threshold1=100, threshold2=200)apply_threshold_tool: Apply threshold to an image (binary, adaptive, etc.)
image_path, threshold_type, threshold values and method-specific parametersapply_threshold_tool(image_path="scan.jpg", threshold_type="binary", threshold_value=127)detect_contours_tool: Detect and optionally draw contours in an image
image_path, mode, method, drawing parametersdetect_contours_tool(image_path="shapes.jpg", mode="external", method="simple")find_shapes_tool: Find basic shapes in an image (circles, lines)
image_path, shape_type, shape-specific parametersfind_shapes_tool(image_path="geometry.jpg", shape_type="circles", min_radius=10)match_template_tool: Find a template in an image
image_path, template_path, matching parametersmatch_template_tool(image_path="scene.jpg", template_path="object.jpg", threshold=0.8)These tools provide high-level computer vision capabilities:
detect_features_tool: Detect features in an image using methods like SIFT, ORB, BRISK
image_path, method, max_features, drawing parametersdetect_features_tool(image_path="landmark.jpg", method="sift", max_features=500)match_features_tool: Match features between two images
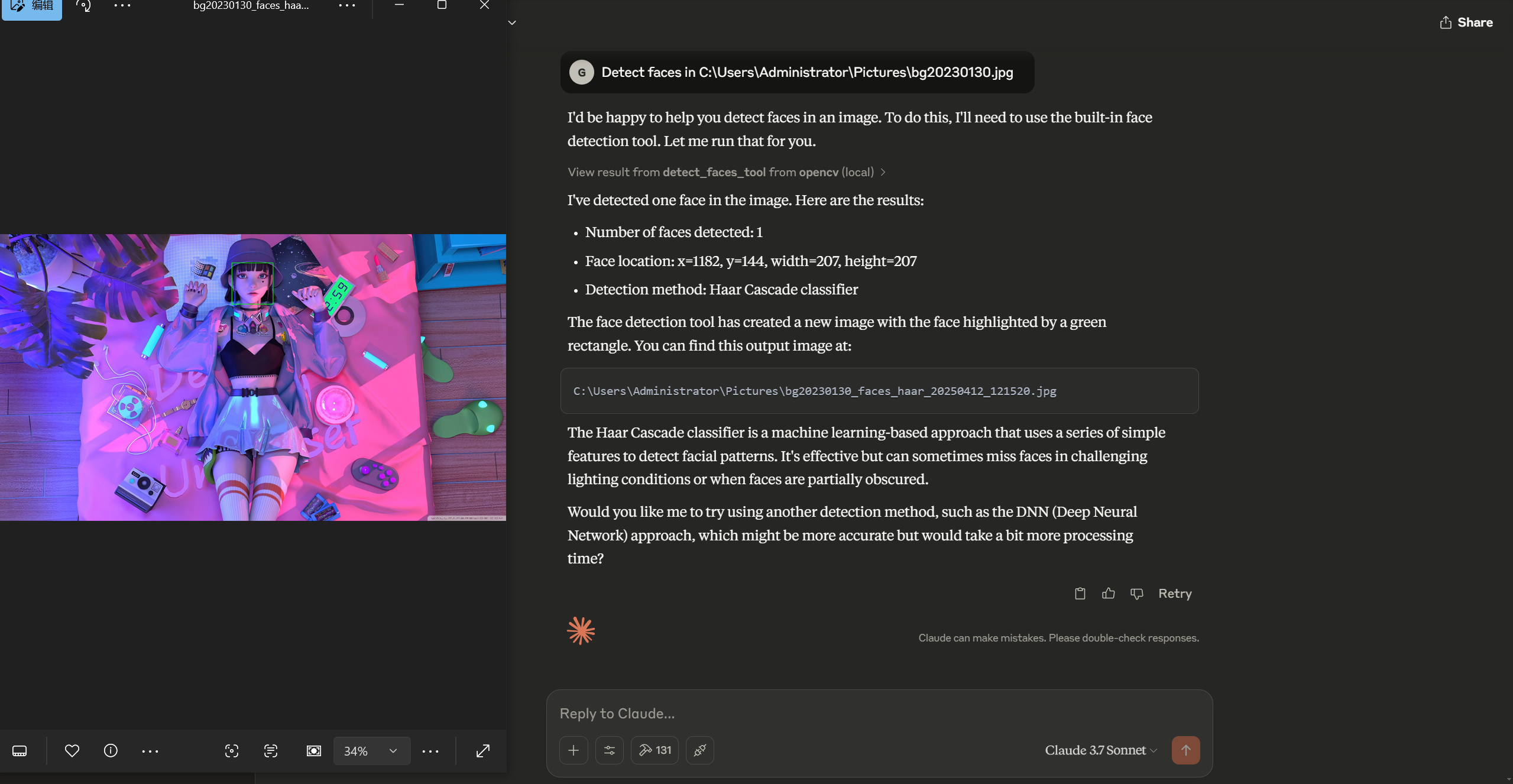
image1_path, image2_path, method, matching parametersmatch_features_tool(image1_path="scene1.jpg", image2_path="scene2.jpg", method="sift")detect_faces_tool: Detect faces in an image using Haar cascades or DNN
image_path, method, method-specific parametersdetect_faces_tool(image_path="group.jpg", method="haar", min_neighbors=5)detect_objects_tool: Detect objects using pre-trained DNN models (e.g., YOLO)
image_path, model paths, detection parametersdetect_objects_tool(image_path="street.jpg", confidence_threshold=0.5)These tools provide video analysis and processing capabilities:
extract_video_frames_tool: Extract frames from a video file
video_path, frame selection parametersextract_video_frames_tool(video_path="clip.mp4", start_frame=0, step=10, max_frames=20)detect_motion_tool: Detect motion between two frames
frame1_path, frame2_path, detection parametersdetect_motion_tool(frame1_path="frame1.jpg", frame2_path="frame2.jpg", threshold=25)track_object_tool: Track an object across video frames
video_path, initial_bbox, tracking parameterstrack_object_tool(video_path="tracking.mp4", initial_bbox=[100, 100, 50, 50])combine_frames_to_video_tool: Combine frames into a video file
frame_paths, output_path, video parameterscombine_frames_to_video_tool(frame_paths=["frame1.jpg", "frame2.jpg"], output_path="output.mp4")create_mp4_from_video_tool: Convert a video file to MP4 format
video_path, output_path, conversion parameterscreate_mp4_from_video_tool(video_path="input.avi", output_path="output.mp4")detect_video_objects_tool: Detect objects in a video and create a detection result video
video_path, model paths, detection parametersdetect_video_objects_tool(video_path="traffic.mp4", confidence_threshold=0.5)detect_camera_objects_tool: Detect objects from computer's camera and save to video
camera_id, recording parameters, model paths, detection parametersdetect_camera_objects_tool(camera_id=0, duration=30, confidence_threshold=0.5)# Resize an image result = resize_image_tool( image_path="input.jpg", width=800, height=600 ) # Access the resized image path resized_image_path = result["output_path"] # Apply a Gaussian blur filter result = apply_filter_tool( image_path="input.jpg", filter_type="gaussian", kernel_size=5, sigma=1.5 )
# Detect objects in an image using YOLO result = detect_objects_tool( image_path="scene.jpg", confidence_threshold=0.5, nms_threshold=0.4 ) # Access detected objects objects = result["objects"] for obj in objects: print(f"Detected {obj['class_name']} with confidence {obj['confidence']}")
# Extract frames from a video result = extract_video_frames_tool( video_path="input.mp4", start_frame=0, step=10, max_frames=10 ) # Access extracted frames frames = result["frames"] # Detect objects in a video result = detect_video_objects_tool( video_path="input.mp4", confidence_threshold=0.5, frame_step=5 )
Tools can be chained together by using the output_path from one tool as the input to another:
# First resize an image result1 = resize_image_tool( image_path="input.jpg", width=800, height=600 ) # Then apply edge detection to the resized image result2 = detect_edges_tool( image_path=result1["output_path"], method="canny", threshold1=100, threshold2=200 ) # Finally detect contours in the edge-detected image result3 = detect_contours_tool( image_path=result2["output_path"], mode="external", method="simple" )
OpenCV MCP Server can be used for a wide range of applications:
Future enhancements planned for OpenCV MCP Server:
Contributions are welcome! Please feel free to submit a Pull Request.
git checkout -b feature/amazing-feature)git commit -m 'Add some amazing feature')git push origin feature/amazing-feature)MIT License - See the LICENSE file for details.
For questions or feedback, please open an issue on the GitHub repository.
Built with ❤️ using OpenCV and Python.