
Dingo
STDIOOfficialData quality evaluation tool with rule-based and LLM assessment for datasets
Data quality evaluation tool with rule-based and LLM assessment for datasets
![]()






![]()
![]()
👋 join us on Discord and WeChat
If you like Dingo, please give us a ⭐ on GitHub!
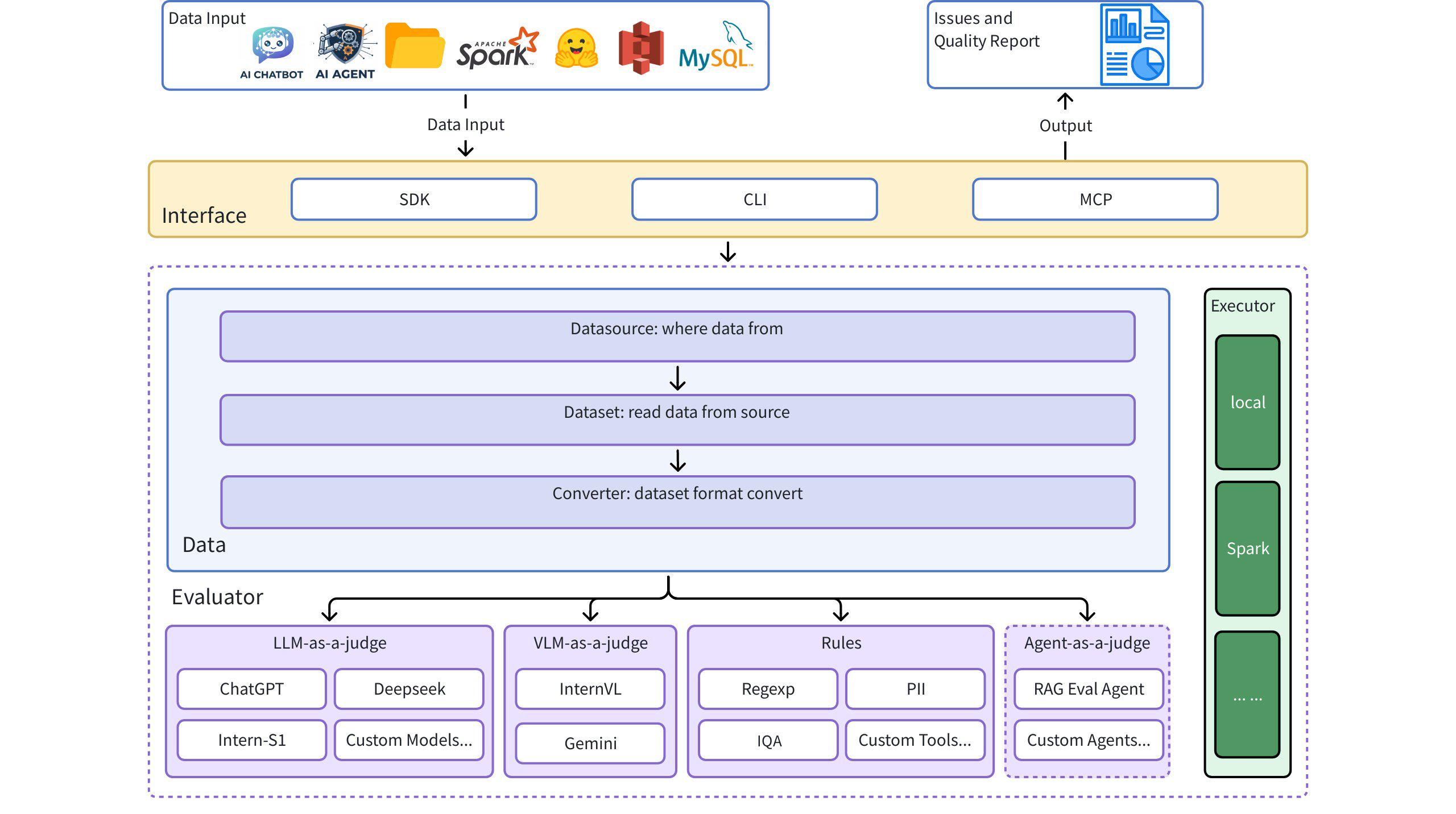
Dingo is a data quality evaluation tool that helps you automatically detect data quality issues in your datasets. Dingo provides a variety of built-in rules and model evaluation methods, and also supports custom evaluation methods. Dingo supports commonly used text datasets and multimodal datasets, including pre-training datasets, fine-tuning datasets, and evaluation datasets. In addition, Dingo supports multiple usage methods, including local CLI and SDK, making it easy to integrate into various evaluation platforms, such as OpenCompass.
pip install dingo-python
from dingo.config.input_args import EvaluatorLLMArgs from dingo.io.input import Data from dingo.model.llm.llm_text_quality_model_base import LLMTextQualityModelBase from dingo.model.rule.rule_common import RuleEnterAndSpace data = Data( data_id='123', prompt="hello, introduce the world", content="Hello! The world is a vast and diverse place, full of wonders, cultures, and incredible natural beauty." ) def llm(): LLMTextQualityModelBase.dynamic_config = EvaluatorLLMArgs( key='YOUR_API_KEY', api_url='https://api.openai.com/v1/chat/completions', model='gpt-4o', ) res = LLMTextQualityModelBase.eval(data) print(res) def rule(): res = RuleEnterAndSpace().eval(data) print(res)
from dingo.config import InputArgs from dingo.exec import Executor # Evaluate a dataset from Hugging Face input_data = { "input_path": "tatsu-lab/alpaca", # Dataset from Hugging Face "dataset": { "source": "hugging_face", "format": "plaintext" # Format: plaintext }, "executor": { "eval_group": "sft", # Rule set for SFT data "result_save": { "bad": True # Save evaluation results } } } input_args = InputArgs(**input_data) executor = Executor.exec_map["local"](input_args) result = executor.execute() print(result)
python -m dingo.run.cli --input test/env/local_plaintext.json
python -m dingo.run.cli --input test/env/local_json.json
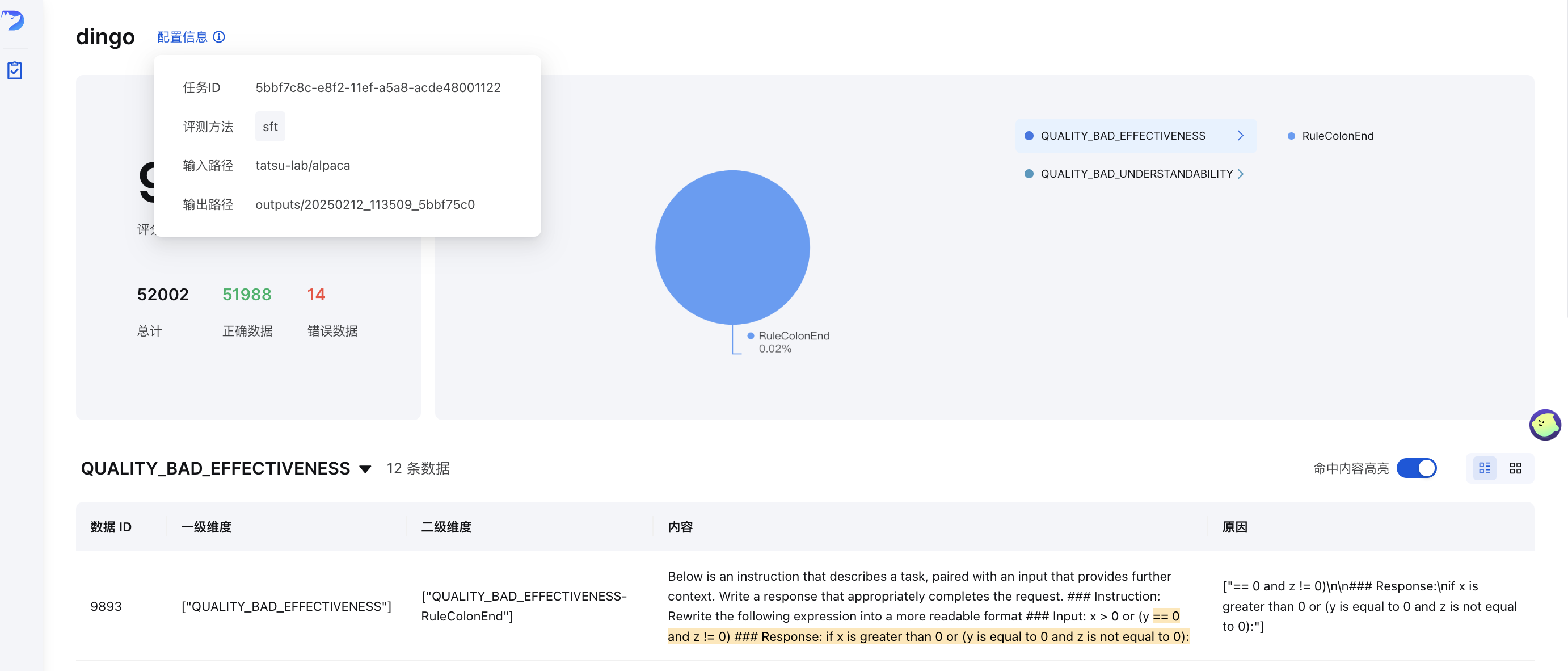
After evaluation (with result_save.bad=True), a frontend page will be automatically generated. To manually start the frontend:
python -m dingo.run.vsl --input output_directory
Where output_directory contains the evaluation results with a summary.json file.
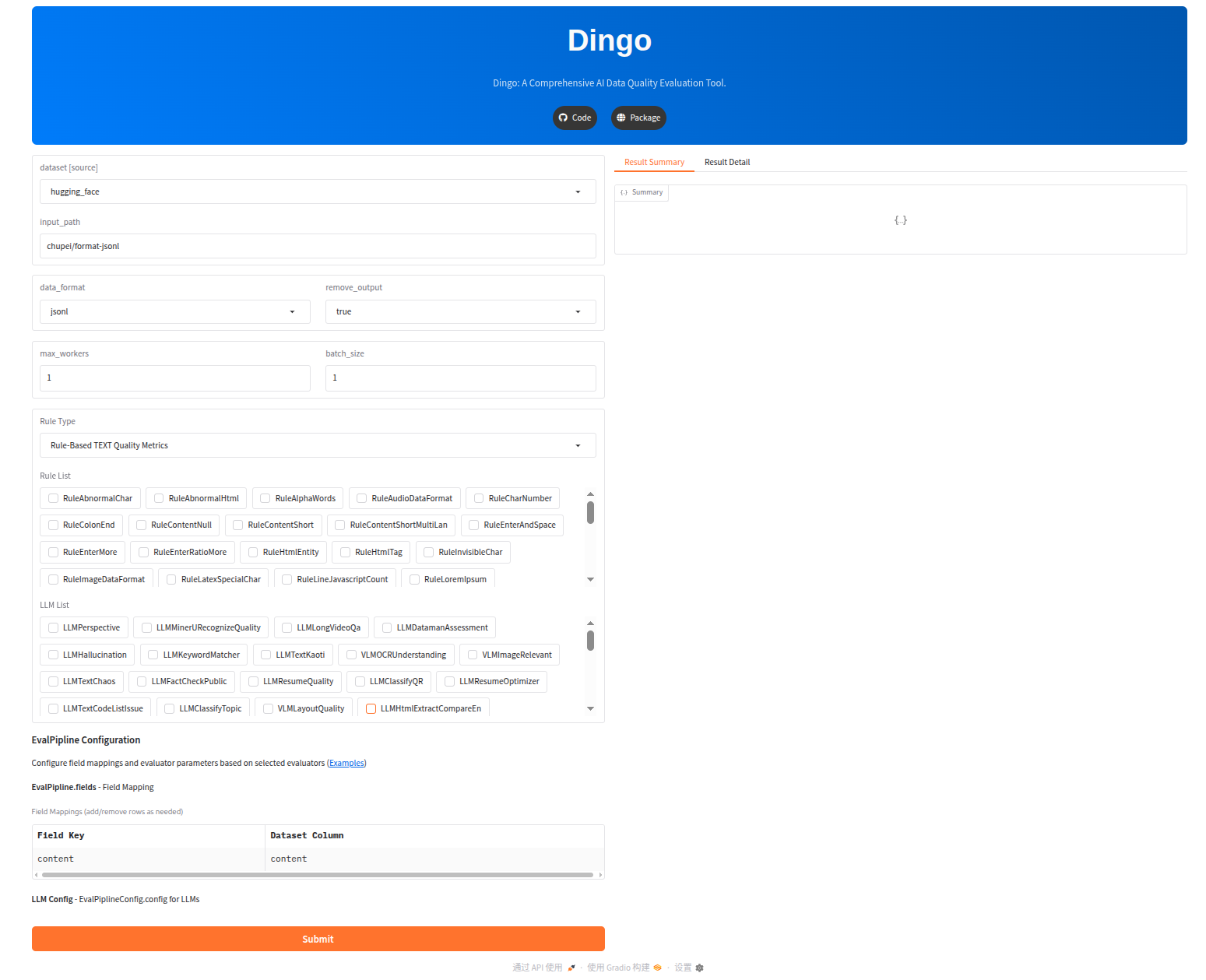
Try Dingo on our online demo: (Hugging Face)🤗
Try Dingo in local:
cd app_gradio python app.py
Experience Dingo interactively with Google Colab notebook: ![]()
Dingo includes an experimental Model Context Protocol (MCP) server. For details on running the server and integrating it with clients like Cursor, please see the dedicated documentation:
To help you get started quickly with Dingo MCP, we've created a video walkthrough:
https://github.com/user-attachments/assets/aca26f4c-3f2e-445e-9ef9-9331c4d7a37b
This video demonstrates step-by-step how to use Dingo MCP server with Cursor.
Dingo provides comprehensive data quality assessment through both rule-based and prompt-based evaluation metrics. These metrics cover multiple quality dimensions including effectiveness, completeness, similarity, security, and more.
📊 View Complete Metrics Documentation →
Our evaluation system includes:
Most metrics are backed by academic sources to ensure objectivity and scientific rigor.
To use these assessment prompts in your evaluations, specify them in your configuration:
input_data = { # Other parameters... "executor": { "prompt_list": ["QUALITY_BAD_SIMILARITY"], # Specific prompt to use }, "evaluator": { "llm_config": { "LLMTextQualityPromptBase": { # LLM model to use "model": "gpt-4o", "key": "YOUR_API_KEY", "api_url": "https://api.openai.com/v1/chat/completions" } } } }
You can customize these prompts to focus on specific quality dimensions or to adapt to particular domain requirements. When combined with appropriate LLM models, these prompts enable comprehensive evaluation of data quality across multiple dimensions.
For detailed guidance on using Dingo's hallucination detection capabilities, including HHEM-2.1-Open local inference and LLM-based evaluation:
📖 View Hallucination Detection Guide →
For comprehensive guidance on using Dingo's two-stage factuality evaluation system:
📖 View Factuality Assessment Guide →
Dingo provides pre-configured rule groups for different types of datasets:
| Group | Use Case | Example Rules |
|---|---|---|
default | General text quality | RuleColonEnd, RuleContentNull, RuleDocRepeat, etc. |
sft | Fine-tuning datasets | Rules from default plus RuleHallucinationHHEM for hallucination detection |
rag | RAG system evaluation | RuleHallucinationHHEM, PromptHallucination for response consistency |
hallucination | Hallucination detection | PromptHallucination with LLM-based evaluation |
pretrain | Pre-training datasets | Comprehensive set of 20+ rules including RuleAlphaWords, RuleCapitalWords, etc. |
To use a specific rule group:
input_data = { "executor": { "eval_group": "sft", # Use "default", "sft", "rag", "hallucination", or "pretrain" } # other parameters... }
If the built-in rules don't meet your requirements, you can create custom ones:
from dingo.model import Model from dingo.model.rule.base import BaseRule from dingo.config.input_args import EvaluatorRuleArgs from dingo.io import Data from dingo.model.modelres import ModelRes @Model.rule_register('QUALITY_BAD_RELEVANCE', ['default']) class MyCustomRule(BaseRule): """Check for custom pattern in text""" dynamic_config = EvaluatorRuleArgs(pattern=r'your_pattern_here') @classmethod def eval(cls, input_data: Data) -> ModelRes: res = ModelRes() # Your rule implementation here return res
from dingo.model import Model from dingo.model.llm.base_openai import BaseOpenAI @Model.llm_register('my_custom_model') class MyCustomModel(BaseOpenAI): # Custom implementation here pass
See more examples in:
from dingo.config import InputArgs from dingo.exec import Executor input_args = InputArgs(**input_data) executor = Executor.exec_map["local"](input_args) result = executor.execute() # Get results summary = executor.get_summary() # Overall evaluation summary bad_data = executor.get_bad_info_list() # List of problematic data good_data = executor.get_good_info_list() # List of high-quality data
from dingo.config import InputArgs from dingo.exec import Executor from pyspark.sql import SparkSession # Initialize Spark spark = SparkSession.builder.appName("Dingo").getOrCreate() spark_rdd = spark.sparkContext.parallelize([...]) # Your data as Data objects input_data = { "executor": { "eval_group": "default", "result_save": {"bad": True} } } input_args = InputArgs(**input_data) executor = Executor.exec_map["spark"](input_args, spark_session=spark, spark_rdd=spark_rdd) result = executor.execute()
After evaluation, Dingo generates:
summary.json): Overall metrics and scoresReport Description:
num_good / totalQUALITY_BAD_COMPLETENESS / totalQUALITY_BAD_COMPLETENESS-RuleColonEnd / totalExample summary:
{ "task_id": "d6c922ec-981c-11ef-b723-7c10c9512fac", "task_name": "dingo", "eval_group": "default", "input_path": "test/data/test_local_jsonl.jsonl", "output_path": "outputs/d6c921ac-981c-11ef-b723-7c10c9512fac", "create_time": "20241101_144510", "score": 50.0, "num_good": 1, "num_bad": 1, "total": 2, "type_ratio": { "QUALITY_BAD_COMPLETENESS": 0.5, "QUALITY_BAD_RELEVANCE": 0.5 }, "name_ratio": { "QUALITY_BAD_COMPLETENESS-RuleColonEnd": 0.5, "QUALITY_BAD_RELEVANCE-RuleSpecialCharacter": 0.5 } }
The current built-in detection rules and model methods focus on common data quality problems. For specialized evaluation needs, we recommend customizing detection rules.
We appreciate all the contributors for their efforts to improve and enhance Dingo. Please refer to the Contribution Guide for guidance on contributing to the project.
This project uses the Apache 2.0 Open Source License.
This project uses fasttext for some functionality including language detection. fasttext is licensed under the MIT License, which is compatible with our Apache 2.0 license and provides flexibility for various usage scenarios.
If you find this project useful, please consider citing our tool:
@misc{dingo,
title={Dingo: A Comprehensive AI Data Quality Evaluation Tool for Large Models},
author={Dingo Contributors},
howpublished={\url{https://github.com/MigoXLab/dingo}},
year={2024}
}